- Research
- Open access
- Published:
ICANet: a simple cascade linear convolution network for face recognition
EURASIP Journal on Image and Video Processing volume 2018, Article number: 51 (2018)
Abstract
Recently, deep convolutional networks have demonstrated their capability of improving the discriminative power compared with other machine learning method, but its feature learning mechanism is not very clear. In this paper, we present a cascaded linear convolutional network, based on independent component analysis (ICA) filters, named ICANet. ICANet consists of three parts: a convolutional layer, a binary hash, and a block histogram. It has the following advantages over other methods: (1) the network structure is simple and computationally efficient, (2) the ICA filter is trained with an unsupervised algorithm using unlabeled samples, which is practical, and (3) compared to deep learning models, each layer parameter in ICANet can be easily trained. Thus, ICANet can be used as a benchmark for the application of a deep learning framework for large-scale image classification. Finally, we test two public databases, AR and FERET, showing that ICANet performs well in facial recognition tasks.
1 Introduction
Convolutional neural networks is a well-known deep learning architecture that has been extensively applied to image recognition. A wide range of attention has been paid to the academe and industry [1–3]. The most important reason is that the deep convolution networks can automatically extract and learn hidden representations of data on a number of blocks consisting of convolutional layer, activation function layer, and max pooling layer. Therefore, how to choose properly parameters and configurations, including the filter sizes, the number of layers, and the pooling function, is a big challenge. AlexNet [1] outpaced LeNet [4] in the ImageNet Large Scale Visual Recognition Challenge in 2012. However, the network structure of AlexNet is growing deeper.
Despite the great successes of deep learning convolutional networks, researchers are not yet clear about its feature learning mechanism and optimal network configuration [5]. Bruna [5] proposed a scattering convolutional network (ScatNet) based on scattering theory, using a fixed filter. ScatNet showed better performance than ConvNet in hand-to-hand recognition and texture discrimination, giving researchers a certain degree of depth for learning the “black box problem” for better understanding. Chan et al. [6] proposed the principle component analysis (PCA) network (PCANet), a shallow and unsupervised learning-intensive deep learning network. PCANet [7–9] leverages the level of PCA convolution filtering to deal with the input image, two hashes, and a block histogram operation to produce the final eigenvector.
Whereas PCANet’s structure is very simple, it has achieved very good performance in most image classification tasks and is used in many fields. For example, Lei [10] obtained good face recognition by concatenating PCANet’s first- and second-stage image codes into a higher-dimensional feature by arranging them in a stack. Zhou [11] implemented the PCANet framework with field programmable gate array hardware. Zheng [12] applied PCANet to age estimation tasks to implement an efficient age estimation system. Chan [6] proposed a PCANet based on deep learning for imaging classification, which include cascaded principal component analysis, binary hashing, and block-wise histograms. Chhatrala [13] used curvelet transform and PCANet to extract discriminative features from masked gait energy image. Prior to PCANet, binarized statistical image features (BSIF) used independent component analysis (ICA) filters to encode the input image in binary, whereas BSIF encoded the image without extending it to the network.
Based on the aforementioned problem, we propose a highly efficient cascaded linear convolutional network structure based on ICA filters, namely ICANet. There are three parts in the ICANet. (1) The linearly cascaded concludes two-layer networks, and the convolution layer is the most important part. The unsupervised learning, ICA algorithm, is used to obtain the convolution filter in each layer. The feature map outputting by the first layer is trained in the second layer. (2) In the second phase of the convolution layer, the binary image coding on the mapping image is processing by the binary hash. At the same time, the number of coding binary image is computed in the first phase filter. (3) The overlapping block is used to encode the binary image into a feature image for block histogram. Each pixel block statistical histogram is expressed by the block method and all histograms are employed to represent a high-dimensional feature.
The main contributions of this paper are as follows.
-
1
We presents a concatenated linear convolution network for facial recognition based on an ICA filter, ICANet. It has only two network layers. This is the big difference with the deep learning method. So ICANet can be calculated faster. At the same time, unsupervised learning is applied to get the ICA filter. Therefore, ICANet is easily used and does not require annotated training samples
-
2
In the feature output stage of ICANet, the overlapping block histogram operations is employed to decrease the information loss
-
3
Our ICANet-based face recognition system adopts unsupervised learning in the feature extraction and feature classification stages. Thus, the system does not need labeled training samples and is easily used
-
4
ICANet has better recognition performance than PCANet in both AR and FERET databases, which can be easy to solve facial expression changes, age changes, occlusions, and light changes. In addition, our method achieves the best results in all four subsets of FERET database comparing with the previous research.
The main differences between this paper and the conference version in the 14th International Computer Conference on Wavelet Active Media Technology and Information Processing (the 14th ICCWAMTIP) [14] are as follows: Firstly, our ICANet-based face recognition system adopts unsupervised learning in the feature extraction and feature classification stages in Section 2. Secondly, we tested the influence of block histogram size on ICANet in Section 3.2. Also, we presented a concrete application of the algorithm in AR database in Section 3.3. Finally, we provided a thorough experiment comparison of the proposed method in FERET database in Section 3.4.
The rest of this paper is organized as follows. Section 2 gives an overview of methods. There are three parts in the ICANet, convolutional layer, binary hash, and block histogram. Then, in Section 3, we present the results from our experiments and compare methods. Finally, the Section 4 concludes the paper.
2 Proposed method
ICANet uses a shallow depth-of-learning network and the network structure shown in Fig. 1. The framework is comprised of three parts: (1) Two-stage convolutional layers: the linearly cascaded concludes two-layer networks, and the convolution layer is the most important part. The unsupervised learning, ICA algorithm, is used to obtain the convolution filter in each layer. The feature map outputting by the first layer is trained in the second layer. (2) Binary hash: In the second phase of the convolution layer, the binary image coding on the mapping image is processing by the binary hash. At the same time, the number of coding binary image is computed in the first phase filter. (3) Overlapped block histogram: The overlapping block is used to encode the binary image into a feature image for block histogram. Each pixel block statistical histogram is expressed by the block method, and all histograms are employed to represent a high-dimensional feature. The convolutional layer of ICANet has two stages, cascaded and linear, so ICANet is a two-layer deep learning network.

ICANet architecture ICANet consists of three parts: (1) two-phase convolutional layer, (2) binary hash, and (3) block histogram
2.1 Convolution layer
The convolution layer has two stages. The input training images are given as N, \(\{I_{i}\}_{i-1}^{N}\). The size of I i is m×n for each face image, and PCANet is assumed to have a filter size of k1×k2 at any phase of the convolutional layer. The ICA algorithm is used to obtain the ICA filter by unsupervised learning in the training sample. So, the two stages of convolution layer are introduced in the following.
The first stage: The block size of image is calculated k1×k2 centered on each pixel in the face image, then the number of image blocks available in image I i is (m−k1/2)×n−k2/2. Giving that all image blocks of the face image I i are vectorized, and matrix X i is sorted, X i after each vector is averaged as \(\overline {\mathbf {X}}_{i}\). The human face images result of N input can be obtained in the following training matrix, X:
The corresponding covariance matrix is
The dimensionality of PCA decreased, and the eigenvector corresponding to n maximum eigenvalues, V, can be obtained as:
where D is the eigenvalue of the covariance matrix, C, and \((\cdot)_{1:L_{1}}\) means the first L1 maximum eigenvalues. To apply the ICA algorithm to estimate the independent component, we split the ICA filter matrix, W, into two parts, as follows.
where Z=VX, and the orthogonal matrix, U, can be estimated by the FastICA algorithm. Finally, after obtaining V and U, the first-stage of ICA filter is calculated by the formula, 5,
The second stage: Suppose the output of the first lth filter defined
where ∗ represents the two-dimensional convolution operation. For each pixel, we get the size of the output image \(\mathcal {T}_{i}^{l}\) as k1×k2 image blocks. Then, these image blocks are vectorized and averaged to form a matrix, as follows.
Here, Y represents all blocks of output images in the first phase after combining the mean of the matrix, \(\overline {\mathbf {Y}}_{i}\) for the i output image. All image blocks are composed of demagnified matrices. The rest of the operation is like that of the first stage. Thus, we get the second-stage filter set, \(\mathbf {W}_{l}^{2}\). The ICANet filter image is shown in Fig. 2.

ICANet filter: The figure shows the filters learned in the ICANet volume base, with the filter size and filter number for both phases set to 11×11 and 8, where a and b are the first and second stages, respectively, of the filter in the ICANet convolutional layer
2.2 Binary hash
In the first stage of the ICANet convolutional layer, the input image, I i , can have the L1 output image, \(I_{i}^{l}\). \(\left \{I_{i}^{l}\ast \mathbf {W}_{l}^{2}\right \}_{l=1}^{L_{2}}\) is the output matrix. Then, the binary coded image is generated by the following equation.
According to expression 8, each pixel is an integer and the value range is \(\left [0,2^{L_{2}-1}\right ]\). Here, the H(·) function means that the positive binary number is 1 otherwise is 0.
2.3 Block histogram
For each binary image, \(\mathcal {T}_{i}^{l},l=1,2,\dots,L_{1}\), the block method is used for each histogram statistic. Then, all the histogram series are used to represent the final feature. Therefore, the input image, I i , can be expressed as follows.
We have two options for leveraging non-overlapping and overlapping block methods. For this study, we use an overlapping block histogram.
From the perspective of the entire ICANet framework, there are three main parameters: filter size, k1 and k2; length of the two-stage filter sets, L1 and L2; and the points of the block histogram-stage block size.
3 Experiments and results
3.1 Parameter setting
In this section, the parameters are set using FERET datasets to generate ICA filters. There are 1196 pictures in the gallery subset whihh are used for unsupervised learning. There are two parameters in the convolution layer, the filter size and the number of filters. In block histogram, how it is blocked and the block size in the histogram should be decided. Furthermore, the detail parameters are shown in Table 1.
3.2 Performance analysis
This section discusses the effect of different parameters in the dup2 dataset of the FERET database on the ICANet algorithm. The main experiment follows
-
Experiment 1: Test the effect of the size of the convolution filter on ICANet
-
Experiment 2: Test the effect of the number of convolution filters on ICANet
-
Experiment 3: Test the impact of the block histogram block sizes on ICANet
3.2.1 Experiment 1
The performance of the size of the filter on ICANet was evaluated. The filter sizes were the same as those in both phases and the value of filter size from 3 ∼17; other parameters were set in table 1. The results is indicated in Fig. 3. The horizontal axis gives the filter size (from 3 to 17), and the vertical axis shows the recognition performance in the range of (0,1].

Effect of filter size on ICANet: Assuming that the filter sizes for both phases of the convolutional layer were equal, the size range gradually increased from 3 ∼17. The results showed that ICANet had the best performance of the facial recognition systems when the filter size was 11
3.2.1.1 Results and discussion:
From the Fig. 3, we can obtain the following conclusions:
-
The recognition performance increase sharply at the very beginning because the filter can get more high-frequency variations of the information in the image. As increasing the filter size, the recognition performance tends to decrease. It can be see that 11 is the best value for the filter size.
-
The filter size is an very significant element for ICANet’s recognition performance. When the filter size is smaller, there are more high-frequency variations of the texture information in the image. But, when the filter size is bigger, the image could have better performance with low-frequency information and the blur effect was removed further.
3.2.2 Experiment 2
In this section, the number of filters on ICANet was evaluated. There are eight filters in the second phase of the convolutional layer, which is the same as that in [6]. The number of filters in the first phase was gradually increased from 4 ∼14, and all other parameters were set by default (see Table 1). The result is shown in Fig. 4. The horizontal axis gives the filter number (from 4 to 14) and the vertical axis shows the recognition performance in the range of (0,1].

Performance of the number of filters in the first stage on ICANet: There were eight filters in the second phase of convolution, and the number of filters in the first phase was gradually increased from 4 ∼14. The results show that ICANet obtained the best performance of facial recognition, as the filter number was 8
3.2.2.1 Results and discussion:
From the Fig. 4, we observed the following:
-
It also showed notable improvement of the recognition performance when the number of filters increased from 4 to 8 in the first phase. As training continues, the performance was slightly jittery. The performance of face recognition achieve the highest point when the number of filters was 8.
-
The number of filters is an important factor for the recognition performance in the convolutional layer on ICANet, because there are more binary images encoded and the amount of information increased when the number of filters in the first stage gradually increased. However, when the number is bigger than 8, redundant information will be increased. Therefore, the face recognition system is a slightly fluctuated.
3.2.3 Experiment 3
This experiment tested the influence of the block histogram size on ICANet. For the sake of simplicity, the block length and width were assumed to be equal. The block size histograms’ block size of 8 was increased to 20 to observe the recognition performance of face recognition system changes. All other parameters used the default settings, see Table 1.
3.2.3.1 Results and discussion:
From Fig. 5, we can draw the following conclusions.
-
When the block gradually increased, the recognition performance was slowly characterized. When the block size was 16×16, the recognition performance was the highest. Then, it decreased, whereas the block size increased.
Fig. 5 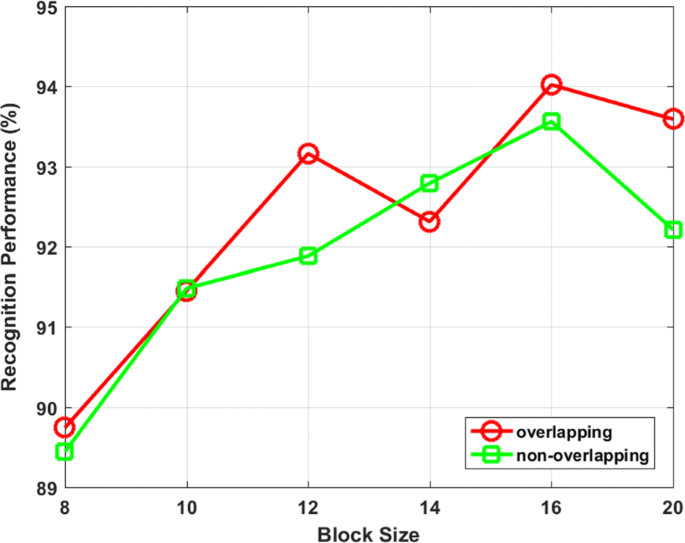
Impact of the histogram block size on ICANet: Assuming that the length and width of the chunks were equal in the ICANet block histogram stage, and both used overlapping and non-overlapping methods, the block size gradually increased from 8 ∼20. The experimental results show that the histogram block size had an impact on ICANet, and the face recognition system had the highest performance when the block size was 16×16
-
Histogram block size had an impact on ICANet, where block histograms overlapped slightly to improve recognition performance.

3.3 AR database
The AR database [15] contains 126 people, about 4000 images. It has face features that include expressions, lighting changes, occlusions, and lighting factors. We selected ICANet for testing a subset of AR. A total of 50 males and 50 females were selected, each having a total of 13 images. For each person, we chose an image with natural expression and no light effects as a gallery, and the other images were divided into four groups (i.e., emoticons, lights, occlusions, and lights + occluders) as test images. All images were pre-aligned and normalized to 64×64 size, as shown in Fig. 6.

Sample image of AR database: The first line of the figure is the image of the natural expression; the second line is the test image, representing four situations from left to right: facial expression, light, occlusion, and light + occlusion
Results and discussion: From the Table 2, we draw the following conclusions.
-
Compared with LBP, P-LBP, and PCANet, ICANet showed the best performance with the AR database, see Table 2
Table 2 ICANet performance comparison with other algorithms using AR ICANet recognition performance on AR data -
ICANet had better recognition performance under the controllable conditions of light, expression, cover, and light + obstruction.
3.4 FERET database
In the 1990s, the FERET face recognition technology project was established jointly by the U.S. Advanced Research Projects Agency and the US Army Research Laboratory. The project created the FERET standard face test database [16]. At present, the standard of the face database and algorithm criteria established in the FERET project are the standard for nascent facial recognition methods.
The FERET database protocol includes 14,051 gray-scale images representing 1199 individuals. The images consist of variations in facial expression, lighting, pose angle, etc. These facial images can be split into five subsets: fa, fb, fc, dup1, and dup2. The images of fa are all natural emotions, generally used as a target set to evaluate the testing algorithm. fa includes 1196 people in 1196 images. fb contains expressions of 1195 changing images. fc represents different light conditions, including 194 images. dup1 contains age variations of corresponding faces, each face with a time range of 0 to 1031 days, containing 722 images. The subset dup2 is a responding set of age changes, with a range of at least six months; it is also a subset of dup1, containing 234 images. Each image is key-point aligned and cropped to a size of 128×128.
Results and discussion: The experimental results are shown in Table 3. After comparing them to many current algorithms, we reach the following conclusions.
-
In general, the recognition performance of ICANet was better than other algorithms;
Table 3 Performance comparison of ICANet with other algorithms using the FERET database fb and fc represent expression and light changes, and dup1 and dup2 represent age changes -
ICANet had the best performance on the dup1 subset with a 96.26% recognition performance;
-
ICANet recognition performance was slightly impaired, because PCANets filtering was only capable of handling second-order information (i.e., correlation). The ICA filter processed data independence, better reflecting the high-level information.
4 Conclusion
In this paper, we presented a concatenated linear convolutional network to the facial recognition based on an ICA filter. ICANet consists of three parts: a two-stage convolutional layer, a binary hash, and block histogram processes. Comparing to the multi-layered deep learning model, ICANet has better efficiency, because it has only two layers in network structure. Additionally, the convolution kernel in ICANet only needs to be trained offline with a few unsupervised ICA algorithms and a few untrained samples. Therefore, the ICANet model had a short development cycle and can be used easily. Finally, experiments were carried out on AR and FERET databases. The experiments demonstrated that ICANet has better robustness with regard to facial recognition tasks, light changes, changes of facial expressions, age change, occlusion problems, etc.
Abbreviations
- ICANet:
-
Independent Component Analysis Network
- PCANet:
-
Principle Component Analysis Network
References
A Krizhevsky, I Sutskever, GE Hinton, in International Conference on Neural Information Processing Systems. Imagenet classification with deep convolutional neural networks (Curran Associates Inc., 2012), pp. 1097–1105.
C Szegedy, W Liu, Y Jia, et al, in 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Going deeper with convolutions, (2015), pp. 1–9.
MD Zeiler, R Fergus, in European Conference on Computer Vision. Visualizing and understanding convolutional networks (Springer, 2014), pp. 818–833.
Y Lecun, L Bottou, Y Bengio, et al, Gradient-based learning applied to document recognition. Proc. IEEE. 86(11), 2278–2324 (1998).
J Bruna, S Mallat, Invariant scattering convolution networks. IEEE Trans. Pattern. Anal. Mach. Intell.35(8), 1872–1886 (2013).
T Chan, K Jia, S Gao, J Lu, Z Zeng, Y Ma, PCANet: a simple deep learning baseline for image classification?. IEEE Trans. Image Process.24(12), 5017–5032 (2015).
D Huang, Y Du, Q He, et al, in Web Technologies and Applications. Scene classification in high resolution remotely sensed images based on PCANet (Springer International Publishing, 2016), pp. 179–190.
B Li, Y Dong, D Zhao, et al, in IEEE, International Conference on Intelligent Transportation Systems. A PCANet based method for vehicle make recognition (IEEE, 2016), pp. 2404–2409.
J Wu, S Qiu, Y Kong, L Jiang, L Senhadji, H Shu, PCANet: an energy perspective. arXiv preprint arXiv:1603.00944. (2016).
L Tian, C Fan, Y Ming, et al, in IEEE International Conference on Digital Signal Processing. Stacked PCA network (SPCANet): an effective deep learning for face recognition (IEEE, 2015), pp. 1039–1043.
Y Zhou, W Wang, X Huang, in IEEE International Symposium on Field-Programmable Custom Computing Machines. FPGA design for PCANet deep learning network (IEEE, 2015), p. 232.
D Zheng, J Du, W Fan, J Wang, C Zhai, in International Conference on Intelligent Computing. Deep learning with PCANet for human age estimation (Springer, 2016), pp. 300–310.
R Chhatrala, D Jadhav, Gait recognition based on curvelet transform and PCANet. Pattern Recog. Image Anal. 27(3), 525–531 (2017).
Y Zhang, T Geng, Y Cai, in International Computer Conference on Wavelet Active Media Technology and Information Processing. A novel network model based ICA filter for face recognition, (2017), pp. 120–123.
AM Martinez, The AR face database. CVC Technical report (1998).
PJ Phillips, H Moon, SA Rizvi, PJ Rauss, The feret evaluation methodology for face-recognition algorithms. IEEE Trans. Pattern. Anal. Mach. Intell. 22(10), 1090–1104 (2000).
T Ahonen, A Hadid, M Pietikainen, Face description with local binary patterns: application to face recognition. IEEE Trans. Pattern. Anal. Mach. Intell. 28(12), 2037–2041 (2006).
X Tan, B Triggs, Enhanced local texture feature sets for face recognition under difficult lighting conditions. IEEE Trans. Image Process. 19(6), 1635–1650 (2010).
J Lu, Y-P Tan, G Wang, Discriminative multimanifold analysis for face recognition from a single training sample per person. IEEE Trans. Pattern. Anal. Mach. Intell. 35(1), 39–51 (2013).
X Tan, B Triggs, in Analysis and Modeling of Faces and Gestures. Fusing Gabor and LBP feature sets for kernel-based face recognition (SpringerBerlin Heidelberg, 2007), pp. 235–249.
N-S Vu, A Caplier, Enhanced patterns of oriented edge magnitudes for face recognition and image matching. IEEE Trans. Image Process. 21(3), 1352–1365 (2012).
N-S Vu, Exploring patterns of gradient orientations and magnitudes for face recognition. IEEE Trans. Inf. Forensic Secur. 8(2), 295–304 (2013).
S Xie, S Shan, X Chen, J Chen, Fusing local patterns of Gabor magnitude and phase for face recognition. IEEE Trans. Image Process. 19(5), 1349–1361 (2010).
SU Hussain, T Napoléon, F Jurie, in British Machive Vision Conference. Face recognition using local quantized patterns, (2012), p. 11.
Z Chai, Z Sun, H Mendez-Vazquez, R He, T Tan, Gabor ordinal measures for face recognition. IEEE Trans. Inf. Forensic Secur. 9(1), 14–26 (2014).
Z Lei, M Pietikäinen, SZ Li, Learning discriminant face descriptor. IEEE Trans. Pattern. Anal. Mach. Intell. 36(2), 289–302 (2014).
C Ding, J Choi, D Tao, LS Davis, Multi-directional multi-level dual-cross patterns for robust face recognition. IEEE Trans. Pattern. Anal. Mach. Intell. 38(3), 518–531 (2016).
Funding
This work is supported by the National Natural Science Foundation of China (No.61702058), the National Key Scientific Instrument and Equipment Development Project of China (No.2013YQ49087903), China Postdoctoral Science and Foundation (No.2017M612948), and the Scientific Research Foundation of CUIT (No.KYTZ201717, J201706).
Availability of data and materials
We can provide the data.
Author information
Authors and Affiliations
Contributions
YZ conducted the experiments and drafted the manuscript. TG implemented the core algorithm. XW designed the methodology. JZ and DG modified the manuscript. All authors read and approved the final manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare that they have no competing interests.
Publisher’s Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is distributed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits unrestricted use, distribution, and reproduction in any medium, provided you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made.
About this article

Cite this article
Zhang, Y., Geng, T., Wu, X. et al. ICANet: a simple cascade linear convolution network for face recognition. J Image Video Proc. 2018, 51 (2018). https://doi.org/10.1186/s13640-018-0288-4
Received:
Accepted:
Published:
DOI: https://doi.org/10.1186/s13640-018-0288-4