- Research
- Open access
- Published:
Quality assessment of image-based biometric information
EURASIP Journal on Image and Video Processing volume 2015, Article number: 3 (2015)
Abstract
The quality of biometric raw data is one of the main factors affecting the overall performance of biometric systems. Poor biometric samples increase the enrollment failure and decrease the system performance. Hence, controlling the quality of the acquired biometric raw data is essential in order to have useful biometric authentication systems. Towards this goal, we present a generic methodology for the quality assessment of image-based biometric modality combining two types of information: 1) image quality and 2) pattern-based quality using the scale-invariant feature transformation (SIFT) descriptor. The associated metric has the advantages of being multimodal (face, fingerprint, and hand veins) and independent from the used authentication system. Six benchmark databases and one biometric verification system are used to illustrate the benefits of the proposed metric. A comparison study with the National Institute of Standards and Technology (NIST) fingerprint image quality (NFIQ) metric proposed by the NIST shows the benefits of the presented metric.
1 Introduction
Biometric systems are being increasingly used in our daily life to manage the access of physical (such as border control) and logical (such as e-commerce) resources. Biometrics uses the authentication factors based on ‘Something that qualifies the user’ and ‘Something the user can do’. The main benefits of this authentication method is the strong relationship between the individual and its authenticator as well as the easiness of its use. Also, it is usually more difficult to copy the biometric characteristics of an individual than most of other authentication methods such as passwords.
Despite the advantages of biometric systems, many drawbacks decrease their proliferation. The main one is the uncertainty of the verification result. By contrast to password checking, the verification of biometric raw data is subject to errors and represented by a similarity percentage (100% is never reached). This verification inaccuracy is due to many reasons such as the variations of human characteristics (e.g., occlusions [1]), environmental factors (e.g., illuminations [2]), and cross-device matching [3]. This kind of acquisition artifacts may deeply affect the performance of biometric systems and hence, decrease their use in real life applications. Moreover, the impact of quality on the system overall performance is also presented by the results of the Fingerprint Verification Competition (FVC) series of competitions (FVC in 2000, 2002, 2004, and 2006) [4]. More specifically, the used databases in FVC 2004 and FVC 2006 are more difficult than the ones in FVC 2002 and FVC 2000, due to the perturbations deliberately introduced. The results show that the equal error rate (EER) in average of the best matching algorithm has increased from 0.96 in FVC 2000 and FVC 2002 to 2.115 in FVC 2004 and FVC 2006. Therefore, controlling the quality of the acquired biometric raw data is considered as an essential step in both enrollment and verification phases. Using the quality information, poor quality samples can be removed during the enrollment or rejected during the verification. Such information could be also used for soft biometrics and multimodal approaches [5,6].
We present in this paper a quality assessment metric of image-based biometric raw data using both information: 1) image quality and 2) pattern-based quality using the scale-invariant feature transformation (SIFT) keypoints extracted from the image. The presented metric has the advantages of being multimodal (face, fingerprint, and hand veins) and independent from the used authentication system.
The outline of the paper is given as follows: Section 4 presents related previous works on quality assessment of biometric raw data. We present in Section 4 the proposed quality assessment metric. Section 4 describes the experimental results obtained for the six trial biometric databases (four for face, two for fingerprint and hand veins, respectively). A comparison study with the NFIQ metric on fingerprints is given in Section 4. The conclusion and some perspectives of this work are given in Section 4.
2 Related works
The quality assessment of biometric raw data is receiving more and more attention in biometrics community. We present in this section an overview of existing biometric image-based quality metrics.
The quality assessment of biometric raw data is divided into three points of view as illustrated in Figure 1 [7]:
-
Character: refers to the quality of the physical features of the individual.
Figure 1 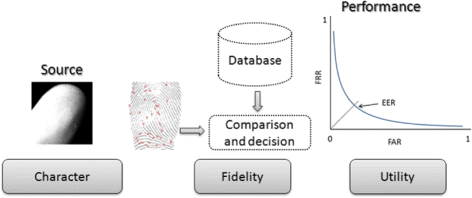
Quality assessment of biometric raw data: character, fidelity, and utility.
-
Fidelity: refers to the degree of similarity between a biometric sample and its source.
-
Utility: refers to the impact of the individual biometric sample on the overall performance of a biometric system.

In biometrics, there is an international consensus on the fact that the quality of a biometric sample should be related to its recognition performance [8]. Therefore, we present in this paper a utility-based quality assessment metric of biometric raw data. In the rest of this section, we present an overview of the existing image-based quality metrics.
Alonso-Fernandez et al. [9] present an extensive overview of existing fingerprint quality metrics which are mainly divided into three major categories:
-
1.
Based on the use of local features of the image;
-
2.
Based on the use of global features of the image;
-
3.
Or addressing the problem of quality assessment as a classification problem.
The presented methods in [9] have shown their efficiency in predicting the quality of fingerprints images. However, these methods are modality-dependent, hence they cannot be used for other kinds of modalities (such as the face). An example of these metrics is the National Institute of Standards and Technology (NIST) fingerprint image quality (NFIQ) metric[10] proposed by the NIST. NFIQ metric is dedicated to fingerprint quality evaluation.
Shen et al. [11] applied the Gabor filters to identify blocks with clear ridge and valley patterns as good quality blocks. Lim et al. [12] combined local and global spatial features to detect low quality and invalid fingerprint images. Chen et al. [13] developed two new quality indices for fingerprint images. The first index measures the energy concentration in the frequency domain as a global feature. The second index measures the spatial coherence in local regions. These methods has shown their efficiency in predicting the quality of fingerprint images. However, they are dedicated for fingerprint modality and could not be used for other modalities such as veins images.
Krichen et al. [1] present a probabilistic iris quality measure based on a Gaussian mixture model (GMM). The authors compared the efficiency of their metric with existing ones according to two types of alterations (occlusions and blurring) which may significantly decrease the performance of iris recognition systems. Chaskar et al. [14] assessed nine quality factors of iris images such as ideal iris resolution (IIR), actual iris resolution (AIR), etc. Other iris quality metrics are presented in [15,16]. However, these methods are used to measure the quality of iris image and cannot be used for other types of modalities.
He et al. [17] present a hierarchical model to compute the biometric sample quality at three levels: database, class, and image quality levels. The method is based on the quantiles of genuine and impostor matching score distributions. However, their model could not be used directly on a single capture (i.e., requires a pre-acquired database).
Zhang and Wang [2] present an asymmetry-based quality assessment method of face images. The method uses SIFT descriptor for quality assessment. The presented method has shown its robustness against illumination and pose variations. Another asymmetry-based method is presented in [18,19]. However, this approach supposes the asymmetry hypothesis hence, could not be used for others types of modalities.
For the finger veins modality, very few are the existing works that predict the quality of finger vein images. We can cite the work presented by Qin et al. [20]. The authors present a quality assessment method of finger vein images based on the Radon transform to detect the local vein patterns. We believe that extensive work should be done in this area since the veins modality is considered as a promising solution to be implemented.
2.1 Discussion
Quality assessment of biometric raw data is an essential step to achieve a better accuracy in real-life applications. Despite this, few researches have been conducted to this point with respect to research activities on performance side. However, most of the existing quality metrics are modality- and matcher-dependent. The others, based on the genuine and impostor matching score distributions, could not be used directly on a single capture (i.e., they require a large number of captures for the same person in order to constitute its genuine score distribution). Therefore, the main contribution of this paper is the definition of a quality metric which can be considered as independent from the used matching system, and also it can be used for several biometric modalities (face, fingerprint, and hand veins images). It detects with a reasonable accuracy three types of alterations that may deeply affect the global performance of the most widely used matching systems. The presented metric is not based on asymmetry hypothesis. Thus, it may be used for several types of modalities (such as fingerprint, face, hand, and finger veins) and can be used directly on a single capture after training the model.
3 Developed metric
The presented metric is designed to quantify the quality of image-based biometric data using two types of information as illustrated in Figure 2. The retained principle is as follows: using one image quality criterion (Section 4) and four pattern-based quality criteria (Section 4), a support vector machine (SVM)-based classification process (Section 4) is performed to predict the quality of the target biometric data.

General scheme of the proposed quality metric.
3.1 No-reference image quality
The image quality assessment is an active research topic which is widely used to validate treatment processes applied to digital images. In the context of image compression, for example, such kind of assessment is used to quantify the quality of the reconstructed image. Existing image quality assessment metrics are divided into three categories: 1) full-reference (FR) quality metrics, where the target image is compared with a reference signal that is assumed to have perfect quality; 2) reduced-reference (RR) quality metrics, where a description of the target image is compared with a description of the reference signal; and 3) no-reference (NR) quality metrics, where the target image is evaluated without any reference to the original one. Despite the acceptable performance of current FR quality algorithms, the need for a reference signal limits their application and calls for reliable no-reference algorithms.
In our study, we have used a no-reference image quality assessment (NR-IQA) index, since the reference image does not exist. The used NR-IQA method in this paper is the blind image integrity notator using discrete cosine transform (DCT) statistics (BLIINDS) index introduced by Saad et al. [21]. This index is based on a DCT framework. This makes it computationally convenient, uses a commonly used transform, and allows a coherent framework. The BLIINDS index is defined from four features, using 17 × 17 image patches centered at every pixel in the image, that are then pooled together:
-
1.
DCT-based contrast feature (υ 1)
Contrast is a basic perceptual attribute of an image. One may distinguish between global contrast measures and the ones that are computed locally (and possibly pooled into one measure post local extraction). The contrast of the k th local DCT patch is computed as follows:
$$ c^{k}(x)=\frac{1}{N} \sum\limits_{i=1}^{N} \frac{x_{AC}^{i}}{x_{DC}} $$((1))where N is the patch size, x DC represents the DC coefficient and the set \(\{x_{\textit {AC}}^{i}|~i=1:N\}\) represents the AC coefficients. Then, the local contrast scores from all patches of the image are then pooled together by averaging the computed values to obtain a global image contrast value υ 1:
$$ \upsilon_{1}=\frac{1}{M} \sum\limits_{i=1}^{M} c^{i}(x) $$((2))where M is the number of local patches.
-
2.
DCT-based structure features (υ 2)
Structure features are derived locally from the local DCT frequency coefficients computed on a patch k. They are based on statistical traits of the DCT histogram for which the DC coefficient is ignored. To measure these statistical traits of the DCT histograms of the patch k, its kurtosis is computed to quantify the degree of its peakedness and tail weight:
$$ \kappa^{k}(x_{AC}) =\frac{E(x_{AC}-\mu)^{4}}{\sigma^{4}} $$((3))where μ is the mean of x AC , and σ is its standard deviation. Then, the resulting values for all patches are pooled together by averaging the lowest tenth percentile of the obtained values to compute the global image kurtosis value υ 2.
-
3.
DCT-based anisotropy orientation (υ 3 and υ 4)
It has been hypothesized that degradation processes damage a scene’s directional information. Consequently, anisotropy, which is a directionally dependent quality of images, was shown by Gabarda and Cristbal [22] to decrease as more degradation is added to the image. The anisotropy measure is computed using the Renyi entropy on DCT image patches along four different orientations θ=0,45,90,135 in degrees. Each patch consists of the DCT coefficients of oriented pixel intensities. We discard the DC coefficient, since the focus is on directional information. Let the DCT coefficients of k th patch of orientation θ be denoted by P θ [k,j], where j is the frequency index of the DCT coefficient. Each DCT patch is then subjected to a normalization of the form:
$$ \tilde{P}_{\theta}[k,j]=\frac{P_{\theta}[k, j]^{2}}{\sum_{j=1}^{N} P_{\theta}[k, j]^{2}} $$((4))where N is the size of the oriented k th patch. Finally, the associated Renyi entropy \(R^{k}_{\theta }\) is computed as:
$$ R^{k}_{\theta} = \frac{1}{1-\beta} \log_{2} \left (\sum\limits_{j=1}^{N}\tilde{P}_{\theta}[k,j]^{\beta} \right) $$((5))where β>1. Finally, the two measures of anisotropy υ 3 and υ 4 are defined as:
$$ \upsilon_{3} = \text{var}(E(R^{k}_{\theta})) \ \text{et} \ \upsilon_{4} = \max(E(R^{k}_{\theta})), \forall k, \forall \theta $$((6))
Due to the fact that the perception of image details depends on the image resolution, the distance from the image plane to the observer and the acuity of the observers visual system, a multiscale approach, is applied to compute the final global score as:
constraints by \(\sum _{j=1}^{4} \sum _{i=1}^{L} {\alpha _{j}^{i}}=1\) and where L represents the number of decomposition level used. The \({\alpha _{j}^{i}}\) values are obtained using the correlation of each criterion (υ i ) with the subjective notes given by human observers [21]. Examples of predicted quality score using BLIINDS index are given in Figure 3. The stronger the image is degraded, the lower the quality index is.

Examples of BLIINDS index on samples of FACES94 database. From left to right, reference image then its noisy images. 13.58, 11.15, 9.35 and 8.50.
3.2 Pattern-based quality
The used pattern-based quality criteria are based on statistical measures of keypoint features. We have used this approach since keypoint features describe, in a stable manner, the regions of the image where the information is important. This approach is widely used in object [23] and biometric recognition [24] issues. For the descriptor vector computation, several methods exist in the literature such as the scale-invariant feature transform [25], shape contexts [26], and speed up robust features (SURF) [27]. In our study, we have used the SIFT algorithm since a comparison study presented by Mikolajczyk and Schmid [28] shows that SIFT outperformed the other methods. SIFT algorithm has been also successfully used in biometric recognition for different modalities such as the veins [24], face [29], fingerprint [30], iris [31] as well as in 3D facial recognition [32].
SIFT algorithm consists of four major stages: 1) scale-space extrema detection, 2) keypoint localization, 3) orientation assignment, and 4) keypoint descriptor. In the first stage, potential interest points are identified, using a difference-of-Gaussian function, that are invariant to scale and orientation. In the second stage, candidate keypoints are localized to sub-pixel accuracy and eliminated if found to be unstable. The third stage identifies the dominant orientations for each keypoint based on its local image patch. The keypoint descriptor in the final stage is created by sampling the magnitudes and orientations of the image gradients in a neighborhood of each keypoint and building smoothed orientation histograms that contain the important aspect of the neighborhood. Each local descriptor is composed of a 4×4 array (histogram). For each coordinate of this array, an eight-orientation vector is associated. A 128-elements (8×(4×4)) vector is then built for each keypoint.
In other words, each image im is described by a set of invariant features X(i m)={k i =(s i , s c i , x i , y i )| i=1:N(i m)} where s i is the 128-elements SIFT invariant descriptor computed near the keypoint k i , (x i ,y i ) is the position of k i in the original image im, s c i is the scale, and N(i m) is the number of detected keypoints in image im. The features extracted are invariant to image scaling and rotation and partially invariant to change in illumination and 3D camera viewpoint. Examples of detected SIFT keypoints are given in Figure 4. From these features, four criteria are retained (see Section 4) to contribute to the quality assessment of the biometric raw data.

Examples of detected SIFT keypoints.
3.3 SVM-based classification
In order to predict biometric sample quality using both information (image quality and pattern-based quality), we use the support vector machine. From all existing classification schemes, a SVM-based technique has been selected due to high classification rates obtained in previous works [33] and to their high generalization abilities. SVMs have been proposed by Vapnik [34] and are based on the structural risk minimization principle from statistical learning theory. SVMs express predictions in terms of a linear combination of kernel functions centered on a subset of the training data, known as support vectors (SV).
Suppose we have a training set {x
i
,y
i
} where x
i
is the training pattern and y
i
the label. For problems with two classes, with the classes y
i
∈{−1,1}, a support vector machine [34] implements the following algorithm. First, the training points {x
i
} are projected into a space  (of possibly infinite dimension) by means of a function Φ(·). The second step is to find an optimal decision hyperplane in this space. The criterion for optimality will be defined shortly. Note that for the same training set, different transformations Φ(·) may lead to different decision functions. A transformation is achieved in an implicit manner using a kernel K(·,·) and consequently the decision function can be defined as :
(of possibly infinite dimension) by means of a function Φ(·). The second step is to find an optimal decision hyperplane in this space. The criterion for optimality will be defined shortly. Note that for the same training set, different transformations Φ(·) may lead to different decision functions. A transformation is achieved in an implicit manner using a kernel K(·,·) and consequently the decision function can be defined as :
with α i∗∈R. The values w and b are the parameters defining the linear decision hyperplane. In SVMs, the optimality criterion to maximize is the margin, that is to say, the distance between the hyperplane and the nearest point Φ(x i ) of the training set. The \(\alpha _{i}^{*}\) which optimize this criterion are obtained by solving the following problem:
where C is a penalization coefficient for data points located in or beyond the margin and provides a compromise between their numbers and the width of the margin. In this paper, we use the RBF kernel:
In order to train models with RBF kernels, we use a python script provided by the LIBSVM library [35]. This script automatically scales training and testing sets. It searches (only for the training set) the best couple (C, γ) of the kernel. The search of the best couple (C, γ) is done using a fivefold cross-validation computation.
Originally, SVMs have essentially been developed for the two classes problems. However, several approaches can be used for extending SVMs to multi-class problems. The method we use in this communication, is called one against one. Instead of learning N decision functions, each class is discriminated here from another one. Thus, \(\frac {N(N-1)} {2}\) decision functions are learned and each of them makes a vote for the affectation of a new point x. The class of this point x becomes then to the majority class after the voting.
4 Experimental results
The goal of the proposed quality metric is to detect, with a reasonable accuracy, three synthetic alterations which may deeply affect the most widely used matching systems. The proposed metric may be considered as independent from the used matching system. An example of its practical use is illustrated in Figure 5. The method predicts the alteration of the input image. Then, depending from the robustness of the used matching system against the predicted alteration, the matching system qualifies the image (good, fair, bad, or very bad quality).

An example of use of the presented method.
In Section 4, we present the experimental protocol followed by the validation process of the proposed metric. The results are then given in Section 4.
4.1 Protocol
Six benchmark databases and one biometric matching algorithm are used in order to validate the proposed metric.
4.1.1 Alteration process
In this study, we introduce three types of synthetic alterations as well as three levels for each type using the MATLAB tool:
-
Blurring alteration: blurring images are obtained using a two-dimensional Gaussian filter. To do so, we use the fspecial (‘gaussian’, hsize, σ) method which returns a rotationally symmetric Gaussian lowpass filter of size hsize with standard deviation σ.
-
Gaussian noise alteration: noisy images are obtained using the imnoise (I, ‘gaussian’, m, v) method. It adds Gaussian white noise of mean m and variance v to the image I.
-
Resize alteration: such kind of altered images are obtained using the imresize (I, scale, ‘nearest’) method. It resizes the image I using a nearest-neighbor interpolation.
Table 1 presents the parameters required of the used alteration MATLAB methods.
Using these alterations, the input vector to SVM is the five retained quality criteria (one for image quality and four pattern-based quality) and the output can belong to ten different classes defined as follows (see Table 2):
-
Class 1 illustrates a reference image.
Table 2 SVM classes definition -
Classes 2 to 10 illustrate three types of alterations and three levels for each type (see Section 4 for details about the introduced alterations).
4.1.2 Benchmark databases
In this study, we use six benchmark databases. For each database, we introduce three types of alterations (blurring, Gaussian noise, and resize alterations) and three levels for each type of alteration. The presented alterations are commonly realistic during the acquisition of biometric raw data, which may deeply affect the overall performance of biometric systems. Finally, we get 60 databases: 6 references and 54 altered databases (i.e., 9 for each reference database):
-
1.
Reference databases
-
FACES94 database [36]: This database is composed of 152 individuals and 20 samples per individual. These images have been captured in regulated illumination, and the variation of expression is moderated (Figure 6).
Figure 6 
Samples from FACES94.
-
ENSIB database [37]: It is composed of 100 individuals and 40 samples per individual. Each sample corresponds to one pose from left to right (Figure 7).
Figure 7 
Samples from ENSIB.
-
FERET database [38,39]: It is composed of 725 individuals with from 5 to 91 samples per individual (the average value is 11). Each sample corresponds to a pose angle, illumination, and expression (Figure 8).
Figure 8 
Samples from FERET.
-
AR database [40]: It is composed of 120 individuals and 26 samples per individual. These included images captured under different conditions of illumination, expression, and occlusion (Figure 9).
Figure 9 
Samples from AR.
-
FVC2002 DB2 database [41]: It is composed of 100 individuals and 8 samples per individual. The database was used during the Fingerprint Verification Competition (FVC 2002) (Figure 10).
Figure 10 
Samples from FVC 2002 DB 2 .
-
Hand veins database [24]: It is composed of 24 individuals and 30 samples per individual. The database has been collected by Telecom & Management SudParis (Figure 11).
Figure 11 
Samples from the hand veins database.
-
-
2.
Altered databases
Using the introduced alterations presented in Section 4, we generated 54 databases from the 6 reference databases: FACES94, ENSIB, FERET, AR, FVC2002 DB2, and the hand veins databases. Figure 12 shows these alterations on a sample from FACES94 database.
Figure 12 
Alterations for a reference image from FACES94. From left to right, reference image then alteration levels 1, 2, and 3. (a) Blurring alteration, (b) Gaussian noise alteration, and (c) Resize alteration.







4.1.3 Biometric matching algorithm
The used biometric matching algorithm is a SIFT-based algorithm [25]. The matching similarity principle used is described in previous works [24]. Each image im is described by a set of invariant features X(i m) as described in Section 4. The verification between two images i m 1 and i m 2 corresponds to the similarity between two sets of features X(i m 1) and X(i m 2). We thus use the following matching method which is a modified version of a decision criterion first proposed by Lowe [25]. Given two keypoints x ∈ X(i m 1) and y ∈ X(i m 2), we say that x is associated to y if:
where C is an arbitrary threshold, d(·,·) denotes the Euclidean distance between the SIFT descriptors and y′ denotes any point of X(i m 2) whose distance to x is minimal but greater than d(x,y):
In other words, x is associated to y if y is the closest point from x in X(i m 2) according to the Euclidean distance between SIFT descriptors and if the second smallest value of this distance d(x,y′) is significantly greater than d(x,y). The significance of the necessary gap between d(x,y) and d(x,y′) is encoded by the constant C. Then, we consider this keypoint x is matched to y iff x is associated to y and y is associated to x. Figure 13 presents an example of a matching resulting from a genuine and an impostor comparison.

Example of matching results resulting from a genuine (on the left) and an impostor comparisons (on the right).
4.2 Validation process
According to Grother and Tabassi [8], biometric quality metrics should predict the matching performance. That is, a quality metric takes a biometric raw data and produces a class or a scalar related to error rates associated to that sample. Therefore, we use the EER which illustrates the overall performance of a biometric system [42]. EER is defined as the rate when both false acceptance rate (FAR) and false reject rate (FRR) are equal: the lower EER, the more accurate the system is considered to be. In order to validate the proposed quality metric, we proceed as follows:
-
Quality criteria behavior with alterations: the first step of the validation process consists of showing the robustness of the used five quality criteria in detecting the introduced alterations: blurring, Gaussian noise, and resize alterations.
-
Learning the multiclass SVM models: for face databases, we learn four multi-class SVM models using the images from the four benchmark databases (one multiclass SVM per benchmark database illustrated by SVMeach) and one multiclass SVM model containing examples from the four benchmark databases (illustrated by SVMall). For the fingerprint and hand veins databases, we learn two multi-class SVM models, respectively. In order to train and to test the multi-class SVM models, we split each benchmark database images into two sets S training and S test in a balanced way (i.e., both sets contain the same ratio of reference and altered images). The choice of the kernel and the selection of the parameters required are presented in Section 4.
-
Quality sets definition: the proposed metric predicts a quality class of the target image. In order to show the utility of this metric, we need to define the quality sets for the used authentication system. Depending from the used authentication system, some alterations may have more impact on its global performance than others. Thereafter, we use the EER to illustrate the global performance of the biometric system.
-
EER value of each quality set: in order to quantify the effectiveness of our quality metric in predicting system performance, we have put each image to a quality set, using its predicted label by our metric. Then, we have calculated the EER value for each quality set. The effectiveness of the method is quantified by how well our quality metric could predict system performance among the defined quality sets. More generally speaking, the more the images are degraded, the more the performance of the overall system will be decreased (illustrated by an increase of its EER value).
4.3 Results
4.3.1 Quality criteria behavior with alterations
In this section, we show the robustness of the used criteria in detecting alterations presented in the previous section. To do so, we use the Pearson’s correlation coefficient between two variables as defined in Equation 13. It is defined as the covariance of the two variables (X and Y) divided by the product of their standard deviation (σ X and σ Y ):
In order to compute the correlation of the used criteria with the three types of alterations, we define for each type of alteration and for each criterion p the variables as follows:
-
X p ={X pk | k=1:4} where X p1 is the set of values of criterion p for the reference databases images, (X p2,X p3,X p4) are the sets of values of criterion p for the altered databases levels 1, 2, and 3, respectively.
-
Alteration levels are represented by the variable Y (1: for the reference databases; 2, 3 and 4: for the altered databases levels 1, 2, and 3). More precisely, Y={y k |y k =1 for k=1:N, y k =2 for k=N+1:2N, y k =3 for k=2N+1:3N and y k =4 for k=3N+1:4N} where N is the size of the four reference databases.
Using the extracted SIFT keypoints and the Pearson’s correlation coefficient, four pattern-based quality criteria are retained to contribute to quality assessment:
-
1.
Keypoints: the number of keypoints detected from image im.
-
2.
DC coefficient: DC coefficient of the matrix M s , with N(i m) rows and 128 columns, related to SIFT invariant descriptor for s i , i=1:N(i m) where N(i m) is the number of detected keypoints for image im.
-
3.
Mean (μ) and
-
4.
Standard deviation (σ) of scales: mean and standard deviation of scales related to the keypoints detected from image im.
Therefore, the vector V used to predict biometric sample quality is a five-dimensional vector containing one image quality criterion and four pattern-based criteria as depicted in Table 3.
Figure 14 shows that the four pattern-based criteria (keypoints, DC coefficient, mean, and standard deviation of scales) are pertinent in detecting the three types of alterations: blurring, Gaussian noise, and resize alterations. The image quality criterion BLIINDS has been shown to be efficient (with a correlation coefficient more than 0.6) in detecting blurring and Gaussian noise alterations. For the resize alteration, BLIINDS has not been shown to be efficient which is not a surprising result since resize alteration does not affect image quality (BLIINDS is a multiresolution NR-IQA algorithm). Moreover, the distortion cards given in Figure 15 show also the efficiency of BLIINDS index (i.e., each feature υ i , i=1:4) in detecting altered images.

Pearson’s correlation coefficients (in absolute value). Correlation between the proposed criteria and the three alterations among the four face databases.

Distortion cards. The cards are related to a slightly altered image (first row) and a highly altered one (second row), respectively. υ i , i=1:4 correspond to the four features used in BLIINDS index computation.
4.3.2 Learning the multi-class SVM models
We learned seven multiclass SVM models: five for face databases and two for hand veins and fingerprint databases. Table 4 presents the accuracy of the learned multiclass SVM models on both training and test sets. We have put the symbol ‘ ×’ at the last two lines, since we have only one multiclass SVM generated per database. Table 4 shows the efficiency of the proposed metric in predicting the three synthetic alterations (blurring, Gaussian noise, and resize) of data, with a valuable ten-class classification accuracy (going from 82.29% to 97.73% on the training set and from 81.16% to 91.1% on the test set). Results for the different databases are similar but not exactly the same. The reason is related to the complexity of the databases incorporating more or less artifacts.
In order to test more the generalization of these results, we have tested the following:
-
We used one of the four face databases for training and the rest three for tests. We obtained a valuable four-class accuracy of 87.84%. The four classes are 1: original; 2, 3, and 4: blurring, Gaussian noise, and resize level 3, respectively. For a ten-class classification, this accuracy decreased to 50.78% due to the different resolution of images in each database. However, the resolution of images to be used for training should be as much as similar for the test images in order to maintain a high accuracy. This is illustrated by the results of the multiclass SVM (SVMall) presented in Table 4 (third and fourth columns). We have obtained good classification results since the images used for training this model contains a set of images from each database.
-
We used a subset of the CASIA-FingerprintV5 [43] (first 100 persons, five images per person, left thumb) of 500 images. The volunteers of CASIA-FingerprintV5 were asked to rotate their fingers with various levels of pressure to generate significant intra-class variations. Using the FVC 2002 DB2 database for learning the multiclass SVM, we classified each of the CASIA-FingerprintV5 500 images into the four categories presented in Table 5 (1 for good, 2 for fair, 3 for poor, and 4 for very poor). We then computed the intra-class matching scores, using the matching algorithm presented in Section 4, of the CASIA-FingerprintV5 database (by taking the first image as reference and the rest for the test). Using the Pearson’s correlation coefficient between the obtained intra-class matching scores and the four categories, we obtained a significant correlation of 0.67. This shows that images classified of good quality by the proposed method provided higher matching scores compared to the images predicted of bad quality; which clarify the benefits of the presented method.
Table 5 Category of quality
4.3.3 Quality sets definition
In order to quantify the robustness of the proposed metric in predicting system performance, we need first to define the quality sets of the used biometric authentication systems. Therefore, we have tested the robustness of the used system against the three alterations presented in Section 4. The EER values are computed using the first image as a reference (single enrollment process) and the rest for the test. Figure 16 shows that all the introduced alterations have an impact on overall performance of the used authentication matching algorithm presented in Section 4. Therefore, we define in Table 5 the quality sets definition for the used matching algorithm.

Impact of alterations on overall performance of the used authentication system among the 4 face databases.
4.3.4 EER value of each quality set
In order to validate the proposed quality metric in predicting the used matching algorithm performance, according to Grother and Tabassi [8], we calculate the EER value of each quality set predicted by the learned multiclass SVM models. Figure 17 shows the EER values of each quality set among the used biometric databases. From this figure, we can deduce several points:

EER values of each quality set among the used biometric databases. Face, fingerprint, and hand veins databases.
-
The proposed metric has shown its efficiency in predicting the used matching system among the six biometric databases. More generally speaking, the more the images are altered, the more the EER values are increasing. This is demonstrated by the increasing curves presented in Figure 17. For the hand veins database, we have obtained a slight increase of EER values (0%: good category to 0.05%: very poor category). This result can be explained by the small size of the hand veins database (24 persons) and the robustness of the used matching system against the introduced alterations.
-
The four curves related to the four face databases, presented in Figure 17, are computed using the four multiclass SVM (one multi-class SVM per database). We have obtained similar curves using the other multiclass SVM model containing examples from the four benchmark databases. This shows the scalability of the presented metric to be used on different types of images (such as the image resolution).
5 Comparison study with NFIQ
In order to show the efficiency of the proposed metric, we present in this section a comparison study with the NFIQ [10]. We have used NFIQ metric proposed by the NIST, since it is the most cited at the literature for the fingerprint modality. NFIQ provides five levels of quality (NFIQ =1 indicates high quality samples, whereas NFIQ =5 indicates poor quality samples). For the comparison with the proposed method (four levels of quality), we consider that the fourth and fifth levels belong to the very bad quality set.
In order to compare the proposed metric with NFIQ, we use the approach suggested by Grother and Tabassi [8] when comparing quality metrics. To do so, we use the Kolmogorov-Smirnov (KS) test [44] which is a nonparametric test to measures the overlap of two distributions: in our case, distributions of scores of genuine and impostors, respectively. More generally speaking, KS test returns a value defined between 0 and 1: for better quality samples, a larger KS test statistic (i.e., higher separation between genuine and impostor distributions) is expected.
Figure 18 illustrates the KS test statistic values of both quality metrics (NFIQ and the presented one). For the three quality sets (bad, fair, and good), Figure 18 shows that the proposed metric (KS statistic going from 0.797 to 0.869) outperformed the NFIQ metric (KS statistic going from 0.632 to 0.82).

Comparison study between the proposed metric and NFIQ: Kolmogorov-Smirnov (KS) test statistic.
6 Conclusion and perspectives
The quality assessment of biometric raw data is a key factor to take into account during the enrollment step when using biometric systems. Such kind of information may be used to enhance the overall performance of biometric systems, as well as in fusion approaches. However, few works exist in comparison to the performance ones. Toward contributing in this research area, we have presented an image-based quality assessment metric of biometric raw data using two types of information (image and pattern-based quality). The proposed metric is independent from the used matching system and could be used to several kind of modalities. Using six public biometric databases (face, fingerprint, and hand veins), we have shown its efficiency in detecting three kinds of synthetic alterations (blurring, Gaussian noise, and resolution).
For the perspectives of this work, we aim to add an additional quality criterion in order to detect luminance alteration, which is also considered as an important alteration affecting biometric systems (mainly, facial-based recognition systems). We aim also to compare the proposed metric with NFIQ using other kind of biometric matching algorithms (such as BOZORTH3 [45] proposed by the NIST). In addition, we are planning to test the efficiency of the presented method on altered images combining the presented alterations, which also represent another kind of real-life alterations. This can be done using the presented criteria and a SVM or a genetic algorithm in order to produce an index between 0% and 100% (i.e., more the index is near 100% better is the quality). Modality-specific alterations could also be used to have a precise analysis of the efficiency of the proposed methodology.
Abbreviations
- BLIINDS:
-
BLind Image Integrity Notator using DCT Statistics
- EER:
-
Equal Error Rate
- FAR:
-
False Acceptance Rate
- FRR:
-
False Rejection Rate
- NFIQ:
-
NIST Fingerprint Image Quality
References
E Krichen, S Garcia Salicetti, B Dorizzi, in IEEE Third International Conference on Biometrics : Theory, Applications and Systems (BTAS). A new probabilistic iris quality measure for comprehensive noise detection, (2007), pp. 1–6.
G Zhang, Y Wang, in Proceedings of the 5th International Symposium on Advances in Visual Computing (ISVC), vol. 5876. Asymmetry-based quality assessment of face images, (2009), pp. 499–508.
N Poh, JV Kittler, T Bourlai, Quality-based score normalization with device qualitative information for multimodal biometric fusion. IEEE Trans. Syst. Man Cybernet. 40, 539–554 (2010).
R Cappelli, D Maio, D Maltoni, JL Wayman, AK Jain, Performance evaluation of fingerprint verification systems. IEEE Trans. Pattern Anal. Mach. Intell. (PAMI). 28, 3–18 (2006).
N Poh, T Bourlai, J Kittler, A multimodal biometric test bed for quality-dependent, cost-sensitive and client-specific score-level fusion algorithms. Pattern Recognit. 43, 1094–1105 (2010).
N Poh, T Bourlai, J Kittler, L Allano, F Alonso-Fernandez, O Ambekar, J Baker, B Dorizzi, O Fatukasi, J Fierrez, H Ganster, J Ortega-Garcia, D Maurer, AA Salah, T Scheidat, C Vielhauer, Benchmarking quality-dependent and cost-sensitive score-level multimodal biometric fusion algorithms. Trans. Inform. Forensics Secur. 4(4), 849–866 (2009).
ISO/IEC 29794-1, Biometric Quality Framework Standard, First Ed. JTC1/SC37/Working Group 3 (2009).
P Grother, E Tabassi, Performance of biometric quality measures. IEEE Trans. Pattern Anal. Mach. Intell. 29, 531–543 (2007).
F Alonso-Fernandez, J Fierrez, J Ortega-Garcia, J Gonzalez-Rodriguez, H Fronthaler, K Kollreider, J Bigun, A comparative study of fingerprint image-quality estimation methods. IEEE Trans. Inform. Forensics Secur. 2, 734–743 (2007).
E Tabassi, CL Wilson, in International Conference on Image Processing (ICIP). A novel approach to fingerprint image quality (IEEE, 2005), pp. 37–40.
L Shen, A Kot, W Koo, in Audio- and Video-based Biometric Person Authentication. Quality measures of fingerprint images (SpringerHeidelberg, 2001), pp. 266–271.
E Lim, X Jiang, W-Y Yau, in IEEE International Conference on Image Processing (ICIP). Fingerprint quality and validity analysis (IEEE, 2002), pp. 469–472.
Y Chen, SC Dass, AK Jain, in 5th International Conference Audio- and Video-Based Biometric Person Authentication (AVBPA), 3546. Fingerprint quality indices for predicting authentication performance (SpringerHeidelberg, 2005), pp. 160–170.
UM Chaskar, MS Sutaone, NS Shah, T Jaison, Iris image quality assessment for biometric application. IJCSI Int. J. Comput. Sci. Issues. 9, 474–478 (2012).
Y Chen, SC Dass, AK Jain, in International Conference on Biometrics (ICB). Localized iris image quality using 2-D wavelets (SpringerHeidelberg, 2006), pp. 373–381.
ND Kalka, J Zuo, NA Schmid, B Cukic, Estimating and fusing quality factors for iris biometric images. Trans. Sys. Man Cyber. Part A. 40, 509–524 (2010).
Q He, ZA Sun, TN Tan, Y Zou, in International Conference on Pattern Recognition (ICPR). A hierarchical model for the evaluation of biometric sample quality (IEEETampa, FL, 2008), pp. 1–4.
XF Gao, SZ Li, R Liu, PR Zhang, in International Conference on Biometrics (ICB’07). Standardization of face image sample quality (SpringerHeidelberg, 2007), pp. 242–251.
J Sang, Z Lei, SZ Li, in Proceedings of the Third International Conference on Advances in Biometrics (ICB). Face image quality evaluation for ISO/IEC standards 19794-5 and 29794-5 (SpringerHeidelberg, 2009), pp. 229–238.
H Qin, S Li, AC Kot, L Qin, in Signal & Information Processing Association Annual Summit and Conference (APSIPA ASC). Quality assessment of finger-vein image (IEEEHollywood, CA, 2012), pp. 1–4.
M Saad, AC Bovik, C Charrier, A DCT statistics-based blind image quality index. IEEE Signal Process. Lett. 17(6), 583–586 (2010).
S Gabarda, G Cristbal, Blind image quality assessment through anisotropy. J. Opt. Soc. Am., 42–51 (2007).
P Parisot, Suivi d’objets dans des s?quences d’images de sc?nes d?formables (PhD thesis, Institut de recherche en Informatique de Toulouse, Toulouse, France, 2009).
P-O Ladoux, C Rosenberger, B Dorizzi, in the 3rd IAPR/IEEE International Conference on Biometrics (ICB’09). Palm vein verification system based on SIFT matching (Springer-VerlagBerlin, Heidelberg, 2009), pp. 1290–1298.
DG Lowe, Distinctive image features from scale-invariant keypoints. Int. J. Comput. Vis. (IJCV). 60, 91–110 (2004).
S Belongie, J Malik, J Puzicha, in International Conference on Computer Vision. Matching shapes (IEEE, 2001), pp. 454–461.
H Bay, A Ess, T Tuytelaars, L Van Gool, Speeded-up robust features (SURF). Comput. Vis. Image Underst. 110, 346–359 (2008).
K Mikolajczyk, C Schmid, A performance evaluation of local descriptors. IEEE Trans. Pattern Anal. Mach. Intell. 27, 1615–1630 (2005).
DR Kisku, A Rattani, E Grosso, M Tistarelli, in 5th IEEE International Workshop on Automatic Identification Advanced Technologies (AUTOID’07). Face identification by SIFT-based complete graph topology (IEEEAlghero, 2007), pp. 63–68.
U Park, S Pankanti, AK Jain, in Proc. SPIE 6944, Biometric Technology for Human Identification. Fingerprint verification using SIFT features (IEEEOrlando, Florida, 2008).
F Alonso-Fernandez, P Tome-Gonzalez, V Ruiz-Albacete, J Ortega-Garcia, in IEEE Proc. Intl. Conf. on Biometrics, Identity and Security (BIDS). Iris recognition based on SIFT features (IEEE, 2009), pp. 1–8.
S Berretti, AD Bimbo, P Pala, BB Amor, M Daoudi, in Proceedings of the 20th International Conference on Pattern Recognition (ICPR). A set of selected SIFT features for 3D facial expression recognition (IEEEIstanbul, 2010), pp. 4125–4128.
G Lebrun, C Charrier, O Lezoray, C Meurie, H Cardot, in the 11th International Conference on Computer Analysis of Images and Pattern (CAIP). Fast pixel classification by SVM using vector quantization, tabu search and hybrid color space (SpringerHeidelberg, 2005), pp. 685–692.
V Vapnik, The Nature of Statistical Learning Theory (Springer, New York, 1995).
C-C Chang, C-J Lin, LIBSVM: a Library for Support Vector Machines (2001). Software available at http://www.csie.ntu.edu.tw/~cjlin/libsvm.
University of Essex, Faces94 Database, Face Recognition Data (1994). http://cswww.essex.ac.uk/mv/allfaces/faces94.html.
B Hemery, C Rosenberger, H Laurent, in International Symposium on Signal Processing and Its Applications (ISSPA), Special Session “Performance Evaluation and Benchmarking of Image and Video Processing”. The ENSIB database : a benchmark for face recognition, (2007).
PJ Phillips, H Moon, SA Rizvi, PJ Rauss, The FERET evaluation methodology for face-recognition algorithms. IEEE Trans. Pattern Anal. Mach. Intell. (PAMI). 22(10), 1094–1104 (2000).
PJ Phillips, H Wechsler, J Huang, P Rauss, The FERET database and evaluation procedure for face recognition algorithms. J. Image Vis. Comput. 16, 295–306 (1998).
AM Martinez, R Benavente, The AR face database. CVC Tech. Report (1998).
D Maio, D Maltoni, R Cappelli, JL Wayman, AK Jain, in International Conference on Pattern Recognition (ICPR’02), 3. Fvc2002: Second fingerprint verification competition (IEEEWashington, DC, USA, 2002), pp. 811–814.
ISO/IEC 19795-1, Information Technology – Biometric Performance Testing and Reporting – Part 1: Principles and Framework. International Organization for Standardization tt.
CASIA-FingerprintV5. http://biometrics.idealtest.org/.
G Saporta, Probabilités, analyse des données et statistique. Editions Technip, 1990.
CI Watson, MD Garris, E Tabassi, CL Wilson, RM McCabe, S Janet, K Ko, Users’s guide to NIST biometric image software (NBIS). Technical report, National Institute of Standards and Technology (NIST) (2007).
Acknowledgements
Portions of the research in this paper use the CASIA-FingerprintV5 collected by the Chinese Academy of Sciences’ Institute of Automation (CASIA).
Author information
Authors and Affiliations
Corresponding author
Additional information
Competing interests
The authors declare that they have no competing interests.
Rights and permissions
Open Access This article is distributed under the terms of the Creative Commons Attribution 4.0 International License (https://creativecommons.org/licenses/by/4.0), which permits use, duplication, adaptation, distribution, and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made.
About this article

Cite this article
El-Abed, M., Charrier, C. & Rosenberger, C. Quality assessment of image-based biometric information. J Image Video Proc. 2015, 3 (2015). https://doi.org/10.1186/s13640-015-0055-8
Received:
Accepted:
Published:
DOI: https://doi.org/10.1186/s13640-015-0055-8