- Research Article
- Open access
- Published:
Co-Occurrence of Local Binary Patterns Features for Frontal Face Detection in Surveillance Applications
EURASIP Journal on Image and Video Processing volume 2011, Article number: 745487 (2011)
Abstract
Face detection in video sequence is becoming popular in surveillance applications. The tradeoff between obtaining discriminative features to achieve accurate detection versus computational overhead of extracting these features, which affects the classification speed, is a persistent problem. This paper proposes to use multiple instances of rotational Local Binary Patterns (LBP) of pixels as features instead of using the histogram bins of the LBP of pixels. The multiple features are selected using the sequential forward selection algorithm we called Co-occurrence of LBP (CoLBP). CoLBP feature extraction is computationally efficient and produces a high-performance rate. CoLBP features are used to implement a frontal face detector applied on a 2D low-resolution surveillance sequence. Experiments show that the CoLBP face features outperform state-of-the-art Haar-like features and various other LBP features extensions. Also, the CoLBP features can tolerate a wide range of illumination and blurring changes.
1. Introduction
Recently, surveillance cameras and Closed-Circuit Television (CCTV) are available in places that are highly occupied with people such as subway stations, airports, universities, and casinos. Increasing the number of cameras makes it a difficult task for the human to effectively monitor many cameras for suspicious activities simultaneously. As a result, much research is conducted to implement an intelligent system that mimics the human brain and achieves the monitoring job automatically with minimum human intervention. Monitoring the people is one task where finding the location of the face is used for surveillance applications; indeed, locating the place of the face is a preliminary step for other surveillance-related applications such as face recognition (i.e., find the identity of the person), emotion recognition, face tracking, and many other applications.
Humans can effortlessly detect and locate faces in real-life; however, locating faces using computer vision technology is not an easy task. Here we come to the problem of face detection for computer vision which can be interpreted as follows: given a still image or a video sequence frames, find the location(s) and size(s) of the face(s) in the frame or image if exist(s) [1].
The face detection problem is tackled by numerous different methods since the 1970s. Face detection surveys in [1, 2] illustrate a very comprehensive study on face detection that covers most aspects of face detection techniques up to 2002. Despite the many approaches and techniques in these surveys, none of these techniques was adequate to perform in real-time basis. The term real-time, in this paper, is interpreted as the ability to process frames with a rate close to the examined sequence frame rate, under the condition that the frame rate ≥15 frames/second, that is, 15 frames/second in [3]. The first technique that could process in real-time basis was introduced in [3] in which it was published after these surveys.
Face detectors techniques can be divided into two main streams [1]: featurebased approach where human knowledge is used to extract explicit face features such as nose, mouth, and ears. then geometry and distances are used to decide on the existence of the face [4–6]. The advantages of this approach are the simple implementation, the high detection rate in simple uncluttered images, and the high tolerance to illumination changes. The disadvantages of this approach are the dramatic performance failure in cluttered and difficult, nonfrontal face, multiple faces, and low-resolution images. The second stream is the image-based approach; in this approach, the face detection problem is treated as a binary pattern recognition problem to distinguish between face and nonface images. This approach is a holistic approach that uses machine learning to capture unique and implicit face features. Most of the works in the last decade, including this work, follow the image-based approach due to the superiority over the featurebased approach from an aspect of the capability to handle low-resolution images, nonfrontal face images, and the possibility to process images in real-time. However, tremendous amount of time (i.e., weeks in [7]) is required to train the detector due to several problems, some of these problems will be explained briefly.
Since the image-based approach is the core of this paper, then it will be discussed. Image-based approaches can be categorized, based on the classification strategy used in the design process, into two subcategories: appearance-based approach and boosting-based approach [8]. Appearance-based approach category is considered as any image-based approach face detector that does not employ the boosting classification methods in it classification stage. However, other classification schemes are used such as neural networks [9, 10], Support Vector Machines (SVM) [11], Bayesian classifiers [12, 13], and so forth. All techniques in the appearance-based approach lack the ability to perform in real-time, and it takes an order of seconds to process an image [8]. The other image-based approach subcategory is the boosting-based approach, this approach started after the successful work of Viola and Jones [3] where high detection rate and high speed of processing (15 frames/second) using the AdaBoost (Adaptive Boosting) algorithm [14] and cascade of classifiers were used. Boosting-based approach is considered as any image-based approach that uses the boosting algorithm in the classification stage.
There are some problems associated with using the boosting-based approach to come about. Simple AdaBoost algorithm mechanism used in Viola and Jones is illustrated in Figure 1. AdaBoost uses a voting scheme from weak classifiers,  , where
, where  is the input image,
is the input image,  is the iteration number. These weak classifiers are used to construct a strong classifier,
is the iteration number. These weak classifiers are used to construct a strong classifier,  . The problem of the boosting algorithm in the face detection context is that each weak classifier,
. The problem of the boosting algorithm in the face detection context is that each weak classifier,  , is trained with a single feature as in [7, 11, 15, 16] following the pattern of the successful work of [3]. However, in earlier iterations, these single feature weak classifiers are capable of achieving a low classification error rate of 10%–30% [7] while in later iterations,
, is trained with a single feature as in [7, 11, 15, 16] following the pattern of the successful work of [3]. However, in earlier iterations, these single feature weak classifiers are capable of achieving a low classification error rate of 10%–30% [7] while in later iterations,  cannot achieve less than 40%–50% error rate.
cannot achieve less than 40%–50% error rate.

AdaBoost training mechanism.
This problem prevents the face detector from achieving a very highly accurate detection (i.e., ≈ 100% accuracy), also it increases the number of small contributors  to achieve the desired accuracy in which will correspondingly increase the training time.
to achieve the desired accuracy in which will correspondingly increase the training time.
Although progresses are made to solve the explained face detection problem, the long training time and the insufficient number of discriminative features remain as challenging issues. The approaches followed in the literature to tackle this problem are either by focusing on improving the type of features or by improving the boosting algorithm, or a combination of both approaches. Haar-like features are used in [3], and extension to the Haar-like features have been proposed in [16–19]; however, Haar-like features have small tolerance to illumination changes [3]. Hence, the Local Binary Patterns Histogram (LBP Histogram) features which proved to have high tolerance to illumination [20] were used in [11], but LBP Histogram features are more computationally expensive than Haar-like features. LBP Histogram features [11] are not meant for real-time applications; they favor high discriminative power over speed. Hence, using these features prevent the face detector from processing images in real-time. Improved Local Binary Patterns (ILBP) features [8, 21] are less computationally expensive than LBP Histogram features; however, the number of ILBP features is limited to the number of pixels of the scanning window so a high detection rate, in comparison to LBP Histogram, cannot be achieved. Further extension to the LBP features is proposed in [22] in which Multi-Block LBP (MB-LBP) features are introduced. It is claimed in [22] that MB-LBP features are more informative than the Haar-like features, and they also have smaller feature vector length; hence, these advantages result to a faster training stage. Multidimensional covariance features in [23] are another type of features, but extracting these features is computationally expensive.
In this work, a type of features called Co-occurrence of Local Binary Patterns features (CoLBP) is proposed. The CoLBP features are used to implement a frontal face detector that is capable to achieve a high-performance rate. This face detector is used for surveillance purposes; it is applied on a low-resolution 2D information from a static camera mounted in a position where mostly frontal faces are captured. The proposed CoLBP features are based on the rotational LBP features [20]. This paper uses the rotational LBP with all possible resolutions in the examined scanning window to capture the maximum possible structure of the window that can be obtained using the rotational LBP operator. Unlike most of the known LBP features extensions in [11, 21, 22] where the pixels of the examined scanning window are transformed to LBP values, then the features are the histogram bins of the LBP values; in this work, the features are the LBP values of the pixels, as explained in Figure 2. Hence, extracting a feature of the proposed features (CoLBP) requires computing one pixel's rotational LBP value whereas in the histogram based LBP features as in [11, 21, 22], it requires to compute all of the examined scanning window pixels LBP values in order to find their histogram bin. Therefore, the CoLBP features have less feature extraction computational overhead than histogram based LBP features. The main contribution of this paper is using the co-occurrence of multiple features to increase the feature's discriminative power. The multiple features are selected using the Sequential Forward Selection (SFS) algorithm. CoLBP features are not only computationally efficient but also provide high discriminative power capable to achieve a high detection rate.

Single CoLBP feature vector extraction without co-occurrence of features.
The rest of the paper is organized such that Section 2 introduces the proposed CoLBP features; this section also gives a brief explanation about the classification scheme used to train the face detector and the post-processing step. The conducted experiments are in Section 3. Finally, the conclusion is given in Section 4.
2. Methodology
Figure 3 illustrates the CoLBP face detector that is based on the proposed CoLBP features. The Co-occurrence of the LBP features (CoLBP) features are built upon the rotational LBP features (see the Appendix for explanation about the rotational LBP features). The cascade of classifiers [3] and GentleBoost algorithm [24] are used to train the CoLBP detector. The multiple detections of the same face are merged using post-processing stage. Subsequent sections will explain in details the proposed CoLBP features as well as the method used to train the face detector using these features.

Illustration of face detection system using CoLBP features.
2.1. Co-Occurrence of Local Binary Patterns (CoLBP) Feature Extraction
LBP features drew much of the attention in object detection in general and face detection specifically due to its discriminative power as well as its high tolerance to illumination changes [11]. Detailed explanation about the LBP features and its feature extraction can be found in the Appendix. The main problem of the simple LBP features is that despite its capability to extract high discriminative face features [11], the number of features is limited to the number of pixels. This issue makes the simple LBP features insufficient to achieve a high-performance rate face detector. Various extensions are presented in the literature to solve this problem such as Sobel-LBP [25], CS-LBP [26], MB-LBP [22].
Despite the high discriminative power of the extended features [11, 22, 25, 26] in comparison to the rotational LBP feature, the features are the histogram bins of a region. Therefore, in the classification stage, in order to transfer the image from the pixel space into the feature space to be classified, all histograms' regions LBP features have to be computed to obtain the regions' distributions.
The proposed CoLBP features have the following advantages.
-
(1)
Less computational overhead than the extended LBP features that uses histogram bins as features as in [11, 22, 25, 26].
-
(1)
(2)Overcomplete set of discriminative face features to achieve an accurate face detector; hence, it solves the problem of insufficient amount of information obtained by the simple LBP features. Overcomple feature vector, in this paper, is a vector that its length exceeds the number of pixels of the examined window.
The CoLBP features proposed in this paper tackles the computation overhead problem by using the rotational  , where
, where  ,
,  correspond to the number of points and radius, respectively. Therefore, the features are the
correspond to the number of points and radius, respectively. Therefore, the features are the  value of the pixels. Hence, in the classification stage, only the desired pixel's
value of the pixels. Hence, in the classification stage, only the desired pixel's  features are extracted. Therefore, CoLBP features are more computationally effective than histogram bins features.
features are extracted. Therefore, CoLBP features are more computationally effective than histogram bins features.
Moreover, in order to overcome the problem of limited features number that prevents the system from providing enough information to achieve high-performance rate; the CoLBP feature vector is constructed by an exhaustive extraction for  for all possible
for all possible  s with different
s with different  values as illustrated in Figure 2. Each
values as illustrated in Figure 2. Each  is considered as a resolution to capture the image structure [11]; hence, having different
is considered as a resolution to capture the image structure [11]; hence, having different  with different
with different  s and
s and  s capture the image structure with different resolutions [11] as it can be visualized through Figure 4. To be consistent throughout the paper, the name CoLBP, which stands for Co-occurrence of LBP features, is called on the feature vector that consists of multiple resolutions
s capture the image structure with different resolutions [11] as it can be visualized through Figure 4. To be consistent throughout the paper, the name CoLBP, which stands for Co-occurrence of LBP features, is called on the feature vector that consists of multiple resolutions  features. Hence, when Section 2.1.1 explains the co-occurrence of features, then it flows as "
features. Hence, when Section 2.1.1 explains the co-occurrence of features, then it flows as " " multiple features from the same vector CoLBP.
" multiple features from the same vector CoLBP.

Multiple resolutions
 on a gray-scale image to illustrate the ability to capture different image structure.
on a gray-scale image to illustrate the ability to capture different image structure.
In order to choose  s for each
s for each  , an experiment is conducted that examines the relation of each possible
, an experiment is conducted that examines the relation of each possible  with a wide range of
with a wide range of  s.
s.  s that achieved the highest
s that achieved the highest  for each
for each  are selected for the CoLBP feature vector. An example of this experiment is shown in Figure 5.
are selected for the CoLBP feature vector. An example of this experiment is shown in Figure 5.

The relation between  and
and  in .
in .
Hence, from Figure 5, the CoLBP feature vector consists of  rotational LBP features extracted from multiple
rotational LBP features extracted from multiple  resolutions. The rotational LBP features used are LBP8,1, LBP9,2, LBP12,1, LBP12,2, LBP16,3, LBP18,4, LBP24,4, LBP24,5, LBP26,6, LBP24,7, LBP24,8, LBP24,9, LBP32,10, and LBP32,11.
resolutions. The rotational LBP features used are LBP8,1, LBP9,2, LBP12,1, LBP12,2, LBP16,3, LBP18,4, LBP24,4, LBP24,5, LBP26,6, LBP24,7, LBP24,8, LBP24,9, LBP32,10, and LBP32,11.
To this end, it is shown how the CoLBP features can have less computational overhead than the histogram bins LBP features. Also, CoLBP has an overcomplete set of carefully selected discriminative features.
2.1.1. Co-Occurrence of Multiple CoLBP Features
The co-occurrence of features task can be defined as finding the joint probability of multiple features occurred simultaneously. Similar approach was recently proposed in [17, 18]. The objective of feature co-occurrence is claiming that a higher discriminative power can be achieved using the co-occurrence of multiple CoLBP features than taking same number of features separately. Therefore, in order to find the joint probability among multiple features, feature binarization is carried on as in [3]. Each feature  for the image
for the image  of the CoLBP has a threshold
of the CoLBP has a threshold  and parity
and parity  calculated using a degenerative decision stump [27] from the training data such that the minimum number of examples are misclassified.
calculated using a degenerative decision stump [27] from the training data such that the minimum number of examples are misclassified.
Having the parameters  , then given an input image
, then given an input image  ,
,  binarizes the input to 1 as being a face detection or 0 as being a nonface detection as in
binarizes the input to 1 as being a face detection or 0 as being a nonface detection as in

 is a single feature value,
is a single feature value,  is a threshold values, and
is a threshold values, and  is the party that indicates the direction of the inequality.
is the party that indicates the direction of the inequality.
This is a single feature binarization as in [3]. It is a specific case of a generalized case where more than one feature occur. Equation (2) shows the generalized form,  , where it binarizes multiple features using(1)
, where it binarizes multiple features using(1)

where  is the number of co-occurred features, each
is the number of co-occurred features, each  has
has  , where
, where  .
.
Therefore,  is a vector which has
is a vector which has  of the highest contributing
of the highest contributing  selected as in the following section.
selected as in the following section.  has
has  possible outcomes.
possible outcomes.
If  is used as a weak classifier for boosting-based approach detector with number of features co-occurrence of
is used as a weak classifier for boosting-based approach detector with number of features co-occurrence of  , then this
, then this  is similar to train each weak classifier with single feature as in many boosting-based approaches for the face detection problem in the literature including, but not limited to, [3, 11, 15, 16].
is similar to train each weak classifier with single feature as in many boosting-based approaches for the face detection problem in the literature including, but not limited to, [3, 11, 15, 16].
2.1.2. CoLBP Feature Selection
The combinations of  in (2) are selected such that a minimum cost is achieved by
in (2) are selected such that a minimum cost is achieved by  . If
. If  , then selecting
, then selecting  for the minimum error is trivial since it is based on selecting one feature
for the minimum error is trivial since it is based on selecting one feature  , and this
, and this  corresponds to the minimum error resulted using the decision stump. However, if
corresponds to the minimum error resulted using the decision stump. However, if  then finding
then finding  which achieves the minimum error is not an easy task. The optimal solution would be using the exhaustive search, where the solution is considered optimal from an aspect that the selected
which achieves the minimum error is not an easy task. The optimal solution would be using the exhaustive search, where the solution is considered optimal from an aspect that the selected  co-occurred features achieve the minimum error. However, in the face detection problem, the feature vector dimension is usually in thousands (i.e., Viola and Jones had feature vector
co-occurred features achieve the minimum error. However, in the face detection problem, the feature vector dimension is usually in thousands (i.e., Viola and Jones had feature vector  ,
,  , where
, where  features). Therefore, there are
features). Therefore, there are  possible number of combinations for selecting
possible number of combinations for selecting  in
in  . As a result, a large number of combinations is possible; hence, many feature selection techniques have been proposed throughout the time, and below are some of them.
. As a result, a large number of combinations is possible; hence, many feature selection techniques have been proposed throughout the time, and below are some of them.
Sequential Backward Selection (SBS) [28] is a top-down approach that starts by a set that comprises all features then deletes features on one-by-one basis, where each deleted feature is the one that has the least contribution to minimize the error. On the other hand, the Sequential Forward Selection (SFS) [29] starts from a set of zero features and adds the feature that leads to minimum error. Both methods are suboptimal feature selection in comparison to the exhaustive search; however, they have the advantage of being less computational expensive than the exhaustive search method, and they are simple to implement. The disadvantage of SFS and SBS methods is the nesting effect in which the addition of the feature in the case of SFS or deletion of the feature in the case of SBS cannot be redone. For instance, in SFS, if a feature is added, then this feature will not be checked again whether it still has a high contribution to minimize the error; therefore, some features might lose their contribution after some iterations while they will still be considered. To solve the nesting issue, a method called Plus-l-Minus-r is introduced in [30] in which it adds  features using SFS and deletes
features using SFS and deletes  features using SBS; however, its main problem is the lack of theoretical approach to choose
features using SBS; however, its main problem is the lack of theoretical approach to choose  and
and  . Also, it is more computationally expensive than SBS or SFS. An optimal decision is made by using the branch and bound method [31]; however, this method's complexity increases exponentially with the required number of features to be selected. The Sequential Forward Floating Selection (SFFS) and Sequential Backward Floating Selection (SBFS) [32] are similar to Plus-l-Minus-r in some sense but instead of being tied up by
. Also, it is more computationally expensive than SBS or SFS. An optimal decision is made by using the branch and bound method [31]; however, this method's complexity increases exponentially with the required number of features to be selected. The Sequential Forward Floating Selection (SFFS) and Sequential Backward Floating Selection (SBFS) [32] are similar to Plus-l-Minus-r in some sense but instead of being tied up by  and
and  , they keep adding and deleting features until minima is achieved. SFFS and SBFS methods are proved to outperform SFS and SBS [32].
, they keep adding and deleting features until minima is achieved. SFFS and SBFS methods are proved to outperform SFS and SBS [32].
From all these techniques a tradeoff between computation feasibility versus optimality is claimed in [32]. In this paper, the SFS is considered for the following reasons.
-
(i)
Despite that SFFS method proved the superiority over SFS [32]; however, same results were obtained when small number of features selection were needed (i.e.,
 ) [32]. Also, as will be proven experimentally in subsequent sections that the CoLBP face features tend to perform better when (
) [32]. Also, as will be proven experimentally in subsequent sections that the CoLBP face features tend to perform better when (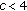 ). Therefore, using SFS or SFFS would give same results. One of the reasons that make SFS and SFFS perform similarly when
). Therefore, using SFS or SFFS would give same results. One of the reasons that make SFS and SFFS perform similarly when  is small (i.e., 4) is that the nesting problem associated with SFS will not affect the system in the same manner as in the situation when several features are used.
is small (i.e., 4) is that the nesting problem associated with SFS will not affect the system in the same manner as in the situation when several features are used. -
(ii)
SFFS is more computationally expensive than SFS [32].
 ) [
) [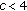 ). Therefore, using SFS or SFFS would give same results. One of the reasons that make SFS and SFFS perform similarly when
). Therefore, using SFS or SFFS would give same results. One of the reasons that make SFS and SFFS perform similarly when  is small (i.e., 4) is that the nesting problem associated with SFS will not affect the system in the same manner as in the situation when several features are used.
is small (i.e., 4) is that the nesting problem associated with SFS will not affect the system in the same manner as in the situation when several features are used.The implemented SFS is a modification to the original SFS [29] as it binarizes the input feature vector and finds the highest contributing  co-occurred features. The SFS algorithm is illustrated in Algorithm 1.
co-occurred features. The SFS algorithm is illustrated in Algorithm 1.
Algorithm 1: SFS algorithm for selecting multiple CoLBP features.
Input:  ,
,  is the training image and
is the training image and  is the class label,
is the class label,  is the weight,
is the weight,
 is the number of co-occurred features;
is the number of co-occurred features;
Output: ;
;
Initialize:  ;
;
(1) Retrieve the calculated CoLBP feature vectors  ,
,  ;
;
(2) Use decision stump to find all features  threshold values
threshold values  and parity values
and parity values  ;
;
for do
do
for do
do
 is concatenation of
is concatenation of  with
with  that is trained with the
that is trained with the  th feature, where
th feature, where  is a temporary
is a temporary
 ;
;
 binarizes all examples
binarizes all examples  using (2);
using (2);
Find the least weighted squared error of adding feature  ,
,  , using
, using  ,
,
where  ,
,  is the Cartesian product of
is the Cartesian product of  terms;
terms;
for do
do
For all  , find the estimated class label
, find the estimated class label  ;
;

end
end
Select  with the
with the  th feature that makes
th feature that makes  ;
;
Update  with
with  ;
;
end
 ,
,  are the conditional joint probability. Hence, for the input image
are the conditional joint probability. Hence, for the input image  , the binarization function
, the binarization function  ,
,  is the Cartesian product of
is the Cartesian product of  terms,
terms,  is the number of co-occurred features, and
is the number of co-occurred features, and  is the class label such that
is the class label such that  is a face object and
is a face object and  is a nonface.
is a nonface.
Therefore,  ,
,  are computed such that
are computed such that

where  is the sample weight.
is the sample weight.
2.2. Classification
The proposed CoLBP features are used to implement a face detector (CoLBP detector). The CoLBP detector is trained using the GentleBoost algorithm [24] and cascade of classifiers [3]. The weak classifiers for the GentleBoost algorithm is  obtained using
obtained using  co-occurred features as explained in the previous sections. Therefore, for each boosting iteration,
co-occurred features as explained in the previous sections. Therefore, for each boosting iteration,  , iteration's specific weak classifier,
, iteration's specific weak classifier,  , with the minimum error,
, with the minimum error,  , is selected. Also, the weight of each sample
, is selected. Also, the weight of each sample  , where
, where  ,
,  is the number of samples, is increased for the misclassified samples and decreased for the correctly classified samples in each iteration of the boosting. Therefore, extra attention is given to the wrongly classified samples. In GentleBoost algorithms, the weighted squared error is used as an error measure. The final strong classifier is
is the number of samples, is increased for the misclassified samples and decreased for the correctly classified samples in each iteration of the boosting. Therefore, extra attention is given to the wrongly classified samples. In GentleBoost algorithms, the weighted squared error is used as an error measure. The final strong classifier is  , where
, where  is a confidence function that optimizes the GentleBoost's cost function. The overall training stage mechanism is as seen in Figure 1, the weak classifier step in Figure 1 is constructed by running Algorithm 1.
is a confidence function that optimizes the GentleBoost's cost function. The overall training stage mechanism is as seen in Figure 1, the weak classifier step in Figure 1 is constructed by running Algorithm 1.
Many variations of boosting algorithms are explained in the literature [14, 19, 24, 27] where all of them have the same explained mechanism but might differ in one or more of either error calculation, weight update and/or feature selection criterion. The GentleBoost [24] was chosen for reasons such as GentleBoost proved the ability to outperform the Discrete AdaBoost and Real AdaBoost in face detection experiments [16], it is numerically stable, and it is simple to implement. Complete discussion about the GentleBoost algorithm can be found in [24].
2.3. Multiple Detections Merging
Applying image-based approach face detectors on an image will cause multiple detections for the same face as seen in Figure 6. The multiple detections occur for two reasons: first, due to the nature of the detection criterion where overlapping scanning window exhaustively search the image with different sizes and locations. Hence, there are windows where the difference in their content is small. Second, the classifier is trained to be insensitive to small localization error [3, 8, 9] so the classifier can handle different face variations. Despite the multiple detections problem, trivially, the number of detections in nonface regions is significantly less than that in the face regions since the classifier is trained to achieve a high accuracy. Therefore, the algorithm used in this paper finds the centroid position of each detection, and then cluster these positions.

Multiple detections merging example.
Furthermore, the multiple detection algorithm is based on a threshold  which decides the minimum number of detections in each cluster to be considered as a detection. All the clusters that do not pass this test are deleted. Afterwards, the detection within each cluster with the highest confidence values is only considered. The confidence of the detection is the value of the strong classifier
which decides the minimum number of detections in each cluster to be considered as a detection. All the clusters that do not pass this test are deleted. Afterwards, the detection within each cluster with the highest confidence values is only considered. The confidence of the detection is the value of the strong classifier  .
.
3. Experiments
Previous sections have introduced the new CoLBP features with its method of extraction and properties studied. Also, the possibility of using the CoLBP features to train a classifier for object detection and a method to merge multiple detections are explained.
In this section, the explained CoLBP features will be applied for the face detection problem, and its performance will be evaluated. Specifically, it will be tested on a real-life 2D surveillance data, BioID dataset, as well as a face/nonface Ole Jensen and Viola and Jones datasets to investigate whether the proposed solution can achieve better detection results than the existing solutions.
The following experiments have been designed for the performance evaluation.
-
(1)
Evaluate the discriminative power of CoLBP features and observe the performance of co-occurrence of multiple features versus the separate ones.
-
(2)
Compare the CoLBP features to other various LBP features extensions presented in the literature.
-
(3)
Evaluate the performance of the CoLBP features-based face detector and compare it to the Haar-like features-based face detector.
-
(4)
Open the area to compare the CoLBP features face detector to the state-of-art face detectors by applying it on the BioID dataset.
-
(5)
Observe the robustness of the CoLBP features towards different illumination and camera blurring noise.
There are several terms that are usually used for face detection evaluation such as Detection Rate ( ), Performance Rate (
), Performance Rate ( ), True Positive (
), True Positive ( ), and False Positive (
), and False Positive ( ).
).  is the ratio between the number of correctly classified faces to the total number of examined faces.
is the ratio between the number of correctly classified faces to the total number of examined faces.  is the ratio of the number of correctly classifying a face image as a face image and nonface image as nonface image to the total number of images evaluated.
is the ratio of the number of correctly classifying a face image as a face image and nonface image as nonface image to the total number of images evaluated.  indicates correctly classifying a face image as a face.
indicates correctly classifying a face image as a face.  detection indicates incorrectly classifying a nonface image as a face.
detection indicates incorrectly classifying a nonface image as a face.
3.1. CoLBP Features As Face Discriminative Features
The CoLBP features explained in Section 2.1 is examined in this experiment to prove the feasibility of providing face discriminative features. This experiment also compares different number of co-occurred features to prove the claim that having a co-occurrence of features produces higher performance rate than considering same number of feature separately.
The GentleBoost algorithm is used to train a classifier using different number of co-occurred features,  . The training and evaluation stages are performed using the Ole Jensen dataset [33] and its mirror images. Ole Jensen dataset consists of
. The training and evaluation stages are performed using the Ole Jensen dataset [33] and its mirror images. Ole Jensen dataset consists of  gray-scale images of size
gray-scale images of size  pixels, where
pixels, where  images are for frontal faces and
images are for frontal faces and  images correspond to nonface images. No extra cropping, resizing and aligning are performed on the dataset; hence, the dataset is used as it was provided in [33]. The training set contained
images correspond to nonface images. No extra cropping, resizing and aligning are performed on the dataset; hence, the dataset is used as it was provided in [33]. The training set contained  images, where
images, where  images and their mirror images correspond to face images and
images and their mirror images correspond to face images and  images and their mirror images correspond to nonface images. Furthermore,
images and their mirror images correspond to nonface images. Furthermore,  and
and  face and nonface images, respectively, and their mirror images are used as evaluation set. The evaluation is based on the performance rate (
face and nonface images, respectively, and their mirror images are used as evaluation set. The evaluation is based on the performance rate ( ) measure.
) measure.
The feature extraction of the CoLBP features follows the explanation in Section 2.1 such that all  radii are extracted. Hence, there are a maximum of 11 possible
radii are extracted. Hence, there are a maximum of 11 possible  s for each window of size
s for each window of size  . Having
. Having  will require a radius of 12 pixel radius excluding the center point; therefore, a diameter of 25 pixels is needed. Based on the different
will require a radius of 12 pixel radius excluding the center point; therefore, a diameter of 25 pixels is needed. Based on the different  s used, which are mentioned in Section 2.1, an overall number of features of
s used, which are mentioned in Section 2.1, an overall number of features of  features are extracted from each window.
features are extracted from each window.
A comparison is made when  ,
,  ,
,  , and
, and  where the comparison is based on training the classifier with
where the comparison is based on training the classifier with  1000 features. Figure 7 shows the generalization error whereas Figure 8 illustrates the training error for the same experiment. The error is calculated as
1000 features. Figure 7 shows the generalization error whereas Figure 8 illustrates the training error for the same experiment. The error is calculated as  . The number of features in Figures 7 and 8 are chosen such that it is unrelated to the number of iterations used to train the classifier. For example, following Section 2.2, the samples weights are updated in every iteration where the iteration consists of 1 CoLBP feature if
. The number of features in Figures 7 and 8 are chosen such that it is unrelated to the number of iterations used to train the classifier. For example, following Section 2.2, the samples weights are updated in every iteration where the iteration consists of 1 CoLBP feature if  or 2 CoLBP features if
or 2 CoLBP features if  , and so forth. Therefore, for fair comparison and to investigate the higher discriminative feature power using the co-occurrence of features then Figures 7 and 8 show the number of features the GentleBoost classifier is trained with.
, and so forth. Therefore, for fair comparison and to investigate the higher discriminative feature power using the co-occurrence of features then Figures 7 and 8 show the number of features the GentleBoost classifier is trained with.

Generalization error for different number of co-occurred features.

Training error for different number of co-occurred features.
Despite that all the  co-occurred features have almost same number of features when the training error converges to zero, all the co-occurred features outperformed the single CoLBP (i.e., CoLBP
co-occurred features have almost same number of features when the training error converges to zero, all the co-occurred features outperformed the single CoLBP (i.e., CoLBP  ) features in the generalization error. The least generalization error resulted using
) features in the generalization error. The least generalization error resulted using  , especially in early iterations. However, due to the fact that SFS reliability to select the best features decreases when the number of selected features increases, then it can be observed from Figures 7 that the performance of the system degrades when it is trained with
, especially in early iterations. However, due to the fact that SFS reliability to select the best features decreases when the number of selected features increases, then it can be observed from Figures 7 that the performance of the system degrades when it is trained with  . Especially if the comparison is conducted in early iterations.
. Especially if the comparison is conducted in early iterations.
To understand the significance achieved using  in comparison to
in comparison to  obtained in Figure 7, then taking an arbitrary number of features, for example 50 features. The difference in
obtained in Figure 7, then taking an arbitrary number of features, for example 50 features. The difference in  between using
between using  and
and  with 50 features is 0.004. So if an image of size
with 50 features is 0.004. So if an image of size  pixels is examined, and exhaustive search scanning window of size
pixels is examined, and exhaustive search scanning window of size  with 1 pixel step size is used, then
with 1 pixel step size is used, then  windows is the total number of windows. Therefore, using
windows is the total number of windows. Therefore, using  with 50 features will lead to an average of 573 wrongly classified windows more than that using same number of features with
with 50 features will lead to an average of 573 wrongly classified windows more than that using same number of features with  .
.
Co-occurrence of other types of features are introduced in the literature such as the co-occurrence of Haar-like features in [17, 18]. Despite it was claimed that the co-occurrence of Haar-like features increased their discriminative power however it was observed that this co-occurrence is prone to overfitting.
From this experiment, the following can be concluded:
-
(i)
CoLBP features are capable of extracting face discriminative features.
-
(ii)
Co-occurred features have higher discriminative power than separate features.
3.2. CoLBP Features versus Various Types of LBP Features
Various extensions to the rotational LBP features are proposed in the literature including, but not limited to, the explained ones in Section 1. Therefore, to further prove the viability of the proposed CoLBP features, comparisons are made with Sobel-LBP [25], MB-LBP [22], and LBP Histogram [11] features. The comparisons are conducted in identical environment to examine the following: performance, training time, which consists of the time consumed to extract the feature vector and the time required to train a model, and classification time, which consists of the time required to extract the trained model features.
In addition to Ole Jensen dataset explained in Section 3.1; Viola and Jones dataset [3, 34] which consists of  gray-scale frontal face images of size
gray-scale frontal face images of size  pixels and
pixels and  gray-scale nonface images of size
gray-scale nonface images of size  is used. Both datasets' mirror images are obtained; hence, a total of
is used. Both datasets' mirror images are obtained; hence, a total of  frontal face images and
frontal face images and  nonface images are available. The datasets are divided into two halves; one half is used for training and the other half is used for evaluation. Therefore, the training dataset consisted of
nonface images are available. The datasets are divided into two halves; one half is used for training and the other half is used for evaluation. Therefore, the training dataset consisted of  face images and
face images and  nonface images of
nonface images of  pixels, and same number, but nonoverlapping, face and nonface images are used for the evaluation stage. The GentleBoost algorithm is used as a classifier. Hence, this experiment does not involve
pixels, and same number, but nonoverlapping, face and nonface images are used for the evaluation stage. The GentleBoost algorithm is used as a classifier. Hence, this experiment does not involve  explained in Section 2.3, and the decision is restricted to whether the detection is a face or a nonface image.
explained in Section 2.3, and the decision is restricted to whether the detection is a face or a nonface image.
It is explained in [35, 36] that LBP Histogram features setup with the combination ( ,
,  , LBP4,1) gives higher performance rate than the LBP Histogram combination in [11] especially on the examined dataset; hence, this combination is used in this experiment. Furthermore, two setups for the Sobel-LBP, which is explained in [25], with
, LBP4,1) gives higher performance rate than the LBP Histogram combination in [11] especially on the examined dataset; hence, this combination is used in this experiment. Furthermore, two setups for the Sobel-LBP, which is explained in [25], with  and
and  subregions are examined.
subregions are examined.
Figure 9 shows  for different types of features using different number of features. It is clear from Figure 9, that CoLBP
for different types of features using different number of features. It is clear from Figure 9, that CoLBP  outperforms all other types of features including the CoLBP
outperforms all other types of features including the CoLBP  . To have a fair comparison between these features, a common
. To have a fair comparison between these features, a common  target threshold is chosen, and the corresponding model that achieves that threshold is considered. Hence, the comparison is conduct under identical environment from an aspect that all models are trained with same dataset, are evaluated on same dataset, used same classifier, and are capable of achieving an arbitrary
target threshold is chosen, and the corresponding model that achieves that threshold is considered. Hence, the comparison is conduct under identical environment from an aspect that all models are trained with same dataset, are evaluated on same dataset, used same classifier, and are capable of achieving an arbitrary  of
of  96%. This arbitrary threshold was chosen since it is the maximum
96%. This arbitrary threshold was chosen since it is the maximum  could be achieved with MB-LBP features, and it was desired that the MB-LBP features to undergo the comparison. Sobel-LBP with
could be achieved with MB-LBP features, and it was desired that the MB-LBP features to undergo the comparison. Sobel-LBP with  pixels subregion was not considered in the comparison as it could not achieve the target
pixels subregion was not considered in the comparison as it could not achieve the target  . Having this threshold, the comparison results are tabulated in Table 1.
. Having this threshold, the comparison results are tabulated in Table 1.
 pixels.
pixels.
Comparison between the CoLBP features and various other LBP features extensions.
From Figure 9, CoLBP  trend outperforms all other experimented LBP extensions; however, judgement of the performance based on the number of features used to train the model is not meaningful. An argument can be raised to defeat such comparisons such that arguing: other LBP features might outperform CoLBP
trend outperforms all other experimented LBP extensions; however, judgement of the performance based on the number of features used to train the model is not meaningful. An argument can be raised to defeat such comparisons such that arguing: other LBP features might outperform CoLBP  when larger number of features are used, yet might be able to classify the images faster if the feature extraction time is faster than CoLBP. Hence, Table 1 proves that CoLBP
when larger number of features are used, yet might be able to classify the images faster if the feature extraction time is faster than CoLBP. Hence, Table 1 proves that CoLBP  not only achieves a higher
not only achieves a higher  than the other examined LBP features but also extracts a trained model feature faster. The reason behind this result is as illustrated in Section 2.1 that the CoLBP features are based on pixels rather than regions. Hence, only the model's specific
than the other examined LBP features but also extracts a trained model feature faster. The reason behind this result is as illustrated in Section 2.1 that the CoLBP features are based on pixels rather than regions. Hence, only the model's specific  values are extracted rather than extracting all the LBP values for all examined window pixels, which is required in LBP extensions that use the histogram bins as features.
values are extracted rather than extracting all the LBP values for all examined window pixels, which is required in LBP extensions that use the histogram bins as features.
Furthermore, as explained in Section 3.1 that the co-occurrence of features not only increases the discriminative power of the features but also significantly reduces the training time by reducing the number of weak classifiers to half. For this reason, it can be seen from Table 1, that CoLBP  training time is less than CoLBP
training time is less than CoLBP  since CoLBP
since CoLBP  required 38 weak classifiers while CoLBP
required 38 weak classifiers while CoLBP  required 18 weak classifiers. Also, CoLBP
required 18 weak classifiers. Also, CoLBP  required 38 features to achieve the target
required 38 features to achieve the target  in comparison to 36 features in the case of CoLBP
in comparison to 36 features in the case of CoLBP  , since each weak classifier is trained with 2 features. Moreover, even though half the number of iterations are required in the CoLBP
, since each weak classifier is trained with 2 features. Moreover, even though half the number of iterations are required in the CoLBP  in comparison to CoLBP
in comparison to CoLBP  , but it can be noticed that the training time is not reduced to half the time. The reason behind it is because of the overhead of using the SFS algorithm in CoLBP
, but it can be noticed that the training time is not reduced to half the time. The reason behind it is because of the overhead of using the SFS algorithm in CoLBP  . Another observation from Table 1 is that having the CoLBP
. Another observation from Table 1 is that having the CoLBP  require less number of features extraction in contrast to the CoLBP
require less number of features extraction in contrast to the CoLBP  (i.e., 38 in CoLBP
(i.e., 38 in CoLBP  versus 36 in CoLBP
versus 36 in CoLBP  ) leads to a faster classification time.
) leads to a faster classification time.
Therefore, the following can be concluded from this experiment.
-
(i)
CoLBP
 features outperform the LBP Histogram, Sobel-LBP, and MB-LBP features.
features outperform the LBP Histogram, Sobel-LBP, and MB-LBP features. -
(ii)
CoLBP
 features require less execution time to extract the trained model features. Hence, faster face detection algorithm can be achieved.
features require less execution time to extract the trained model features. Hence, faster face detection algorithm can be achieved. -
(iii)
Further proved Section 2.1 that CoLBP
 not only outperforms CoLBP
not only outperforms CoLBP 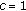 but also requires less training time and has faster classification time.
but also requires less training time and has faster classification time.
 features outperform the LBP Histogram, Sobel-LBP, and MB-LBP features.
features outperform the LBP Histogram, Sobel-LBP, and MB-LBP features. features require less execution time to extract the trained model features. Hence, faster face detection algorithm can be achieved.
features require less execution time to extract the trained model features. Hence, faster face detection algorithm can be achieved. not only outperforms CoLBP
not only outperforms CoLBP 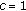 but also requires less training time and has faster classification time.
but also requires less training time and has faster classification time.3.3. CoLBP Face Detector
The CoLBP features are used to train a face detector using the cascade of classifiers technique in [3]. This experiment aims to prove that the CoLBP features are capable to achieve a face detector with a low  of ≈ 1 in
of ≈ 1 in  examined window, this number is chosen as it is considered to what a face detector should have to be considered for practical applications [7], and
examined window, this number is chosen as it is considered to what a face detector should have to be considered for practical applications [7], and  of >90%.
of >90%.  and
and  values are chosen to coincide with the Viola and Jones detector [3] in order to achieve a fair comparison between CoLBP detector and Haar-like feature based detector.
values are chosen to coincide with the Viola and Jones detector [3] in order to achieve a fair comparison between CoLBP detector and Haar-like feature based detector.
Despite the fact that we cannot judge which number of co-occurred features of  performs better; however, it is clear from Figure 7 that CoLBP features with
performs better; however, it is clear from Figure 7 that CoLBP features with  has the least generalization error in earlier iterations. This is preferred since less number of features is required to reach the desired detection accuracy; hence, a faster classification speed is resulted. Therefore,
has the least generalization error in earlier iterations. This is preferred since less number of features is required to reach the desired detection accuracy; hence, a faster classification speed is resulted. Therefore,  is used to train the cascade of classifiers.
is used to train the cascade of classifiers.
The  frontal face images explained in Section 3.2 are used in this experiment. On the other hand, ≈ 20,000 nonface images are downloaded from the World Wide Web; these images were manually investigated to ensure that they do not contain any faces. The images were downsampled with different ratios to increase their number. A total of ≈ 120,000 nonface images were obtained. These images are of bigger resolution than the scanning windows. For example if an image is of size
frontal face images explained in Section 3.2 are used in this experiment. On the other hand, ≈ 20,000 nonface images are downloaded from the World Wide Web; these images were manually investigated to ensure that they do not contain any faces. The images were downsampled with different ratios to increase their number. A total of ≈ 120,000 nonface images were obtained. These images are of bigger resolution than the scanning windows. For example if an image is of size  pixels, and we use exhaustive search scanning window of size
pixels, and we use exhaustive search scanning window of size  with one pixel step, then
with one pixel step, then  nonface windows are obtained. Therefore based on this example, the large number of nonface images can be imagined.
nonface windows are obtained. Therefore based on this example, the large number of nonface images can be imagined.
On each stage in the cascade of classifiers, a randomly selected  face images are used for training and randomly selected
face images are used for training and randomly selected  face images are used for validation, under the condition that the training and validation set have no image in common. Also,
face images are used for validation, under the condition that the training and validation set have no image in common. Also,  nonface images are used for each stage using the bootstrap strategy [3, 11] such that each step is trained with the misclassified nonface images by all previous stages. Furthermore, each stage is designed to achieve a minimum of 99% TP and a maximum of stage's dependant
nonface images are used for each stage using the bootstrap strategy [3, 11] such that each step is trained with the misclassified nonface images by all previous stages. Furthermore, each stage is designed to achieve a minimum of 99% TP and a maximum of stage's dependant  . The stage's
. The stage's  can be found from Table 2 by taking the ceiling of each
can be found from Table 2 by taking the ceiling of each  to nearest one decimal place (i.e.,
to nearest one decimal place (i.e.,  ).
).
After 9 stages, the minimum achieved  using the CoLBP features is
using the CoLBP features is  before depleting all nonface images dataset. The nonface dateset is depleted since the bootstrap strategy is used in training the cascade of classifiers. Table 2 illustrates the number of features,
before depleting all nonface images dataset. The nonface dateset is depleted since the bootstrap strategy is used in training the cascade of classifiers. Table 2 illustrates the number of features,  , and
, and  of each stage.
of each stage.
Comparison between Table 2 and Viola and Jones detector, where both have same objective of achieving total  , and knowing that CoLBP detector is trained with less number of face training dataset than Viola and Jones detector (i.e.,
, and knowing that CoLBP detector is trained with less number of face training dataset than Viola and Jones detector (i.e.,  faces in the CoLBP detector versus
faces in the CoLBP detector versus  faces in Viola and Jones detector), shows that the CoLBP detector requires only
faces in Viola and Jones detector), shows that the CoLBP detector requires only  CoLBP
CoLBP  features while Viola and Jones requires
features while Viola and Jones requires  Haar-like features. Also the CoLBP features are selected from
Haar-like features. Also the CoLBP features are selected from  features whereas the Haar-like features are selected from
features whereas the Haar-like features are selected from  features. Hence, it can be concluded that the CoLBP features cannot only extract discriminative face features to achieve a low total
features. Hence, it can be concluded that the CoLBP features cannot only extract discriminative face features to achieve a low total  of
of  but also require less number of features than Haar-like features in Viola and Jones detector, which indicates that the CoLBP features have higher discriminative power than the Haar-like features.
but also require less number of features than Haar-like features in Viola and Jones detector, which indicates that the CoLBP features have higher discriminative power than the Haar-like features.
3.4. CoLBP Detector for Surveillance Application and Comparison to the Haar-Like Detector
The implemented CoLBP detector performance is evaluated on a real-life scenario as well as its performance is compared to the state-of-the-art Haar-like detector. The evaluation dataset is a real-life footage from a realistic environment where data became available to the University of Toronto team for research purposes. The footage is taped by a camera mounted on the ceiling in vantage to capture frontal faces. The footage is an RGB colorspace sequence and is of Codec Video 1 format with video rate of 5 frames/second. Also, the sequence is of low-resolution of size  pixels, with decent illumination, and has multiple faces but noncrowded area. Faces appear in different sizes up to
pixels, with decent illumination, and has multiple faces but noncrowded area. Faces appear in different sizes up to  pixels.
pixels.
A total of 171 frames are extracted from the sequence where these frames contain all the frontal faces in the sequence in addition to some frames for vacant area. 105 frames are for single frontal face in different positions in order to examine the performance with different face sizes. 21 frames are for two people appearing in the screen to illustrate the ability of detecting more than one face, and finally 45 frames are for images where either a vacant place or nonfrontal faces appear in the scene to inspect the false positive detection tolerance. Some of the real-life frames are shown in Figure 10

Sample frames of the examined real-life sequence to give an impression about the examined environment and to illustrate the different face sizes appearing in the sequence.
For comparison purposes, the CoLBP detector is compared to the state-of-the-art Lienhart detector [15] (hereafter Haar-like detector). haarcascade_frontalface_alt model is used. This model is chosen since the detector is trained with the same boosting algorithm as the CoLBP detector, which is the GentleBoost. This detector is considered for comparison for several reasons, first its implementation is very close to the successful work of Viola and Jones detector. Furthermore, just like the CoLBP detector, Haar-like detector's weak classifier is based on decision stump. Furthermore, despite there are several extensions to the Haar-like features proposed in the literature as in [17, 19]; however, many papers compare their results with this Haar-like detector since it is available in OpenCV.
The used scanning window is similar to Viola and Jones [7] with a size of  pixels. The scanning window is shifted by
pixels. The scanning window is shifted by  , where
, where  is the image downsampling factor,
is the image downsampling factor,  is the shifting parameters, and
is the shifting parameters, and  is rounding operator.
is rounding operator.  downsamples the image by a factor of 1.25 until any dimension of the image becomes smaller than the scanning window.
downsamples the image by a factor of 1.25 until any dimension of the image becomes smaller than the scanning window.  is the shifting parameter that is fixed to 1.
is the shifting parameter that is fixed to 1.
The Free Receiver Operator Characteristic (FROC) is plotted for CoLBP detector and Haar-like detector for all operating points. FROC is very similar to ROC, but it plots the detection rate  versus number of false positive detections (
versus number of false positive detections ( ) instead of
) instead of  rate. The parameter
rate. The parameter  explained in Section 2.3 is used to change the operating points of the detectors.
explained in Section 2.3 is used to change the operating points of the detectors.
The method of evaluation used in this paper is similar to the proposed method in [37] but only the horizontal, vertical and scale errors are considered while the rotation error is dropped. The rotation error is dropped since the CoLBP detector is to be used for surveillance purposes from a camera mounted on the ceiling; hence, only straight with no in-plane rotation is expected; thus, keeping the rotation error penalty biases the decision since it will not occur. The scaling, horizonal and vertical errors are measured between the detected eyes with respect to the manually located eye.
Furthermore, the CoLBP detector and Haar-like detector output the size and location of the face's bounding box. On the other hand, the used method of evaluation requires the position of the centers of the eyes. Therefore, the location of the eyes is estimated from the bounding box output by running the detectors on many examples.
A correct face detection is considered when the detected eyes lie within strict face detection criterion such that the acceptable range is  scaling error and
scaling error and  horizontal and vertical errors [37] from the manually located eye location. Figure 11 shows the FROC for the CoLBP detector versus Haar-like detector.
horizontal and vertical errors [37] from the manually located eye location. Figure 11 shows the FROC for the CoLBP detector versus Haar-like detector.

FROC for the CoLBP and Haar-like detectors using error tolerance of
 scaling and
scaling and
 vertical and horizontal errors.
vertical and horizontal errors.
It can be observed from Figure 11 that the CoLBP detector outperforms the Haar-like detector. It can also be noticed that the Haar-like detector is more consistent with its result throughout different operating points if compared to the CoLBP detector. The reason behind the consistency issue is that the CoLBP detector is trained using two different training datasets Ole Jensen and Viola and Jones; hence, the training face images are not aligned perfectly (i.e., consistent place of the eyes and consistent cropped face area), also to mention that Viola and Jones faces dataset itself is aligned roughly as mentioned in [3]. Therefore, insensitivity to small face error occurs. While on the other hand, we have no knowledge about the training datasets used in the Haar-like detector [15], but it can be concluded from Figure 11 that the training dataset is consistent and aligned; hence, the Haar-like detector is less insensitive to small face error than our used dataset. Therefore, the following can be concluded.
-
(i)
CoLBP detector outperforms the Haar-like detector with 5.50% detection rate (using the operating point that achieves the highest detection rate for both detectors).
-
(ii)
CoLBP features have a higher discriminative power than the Haar-like features. The CoLBP detector with only
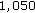 CoLBP features distributed over 9 stages could outperform the Haar-like detector which is trained with
CoLBP features distributed over 9 stages could outperform the Haar-like detector which is trained with  2,122 Haar-like features distributed over 20 stages [15].
2,122 Haar-like features distributed over 20 stages [15]. -
(iii)
CoLBP detector requires less time to train the classifier than the Haar-like detector. Both detectors are trained using the GentleBoost algorithm and using the decision stump as weak classifier; hence, selecting
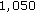 features from a pool of
features from a pool of 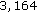 features is less complicated than selecting ≈ 2,122 features from a pool of
features is less complicated than selecting ≈ 2,122 features from a pool of  extended Haar-like features [16].
extended Haar-like features [16]. -
(iv)
Haar-like detector outperforms the CoLBP detector when
 while CoLBP detector outperforms Haar-like detector afterwards. Therefore, the choice of the desired detector can be an application dependent; however, the training complexity difference explained in the previous point might play a crucial factor on the decision.
while CoLBP detector outperforms Haar-like detector afterwards. Therefore, the choice of the desired detector can be an application dependent; however, the training complexity difference explained in the previous point might play a crucial factor on the decision.
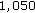 CoLBP features distributed over 9 stages could outperform the Haar-like detector which is trained with
CoLBP features distributed over 9 stages could outperform the Haar-like detector which is trained with  2,122 Haar-like features distributed over 20 stages [
2,122 Haar-like features distributed over 20 stages [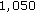 features from a pool of
features from a pool of 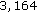 features is less complicated than selecting ≈ 2,122 features from a pool of
features is less complicated than selecting ≈ 2,122 features from a pool of  extended Haar-like features [
extended Haar-like features [ while CoLBP detector outperforms Haar-like detector afterwards. Therefore, the choice of the desired detector can be an application dependent; however, the training complexity difference explained in the previous point might play a crucial factor on the decision.
while CoLBP detector outperforms Haar-like detector afterwards. Therefore, the choice of the desired detector can be an application dependent; however, the training complexity difference explained in the previous point might play a crucial factor on the decision.3.5. Detection Rate Sensitivity to Face Decision Criterion Parameters
This experiment is conducted to find the capability of the CoLBP detector to detect faces using the same evaluation dataset in the previous section however examined with wide range of error tolerance instead of the strict method of evaluation. The error tolerance  is changed from 0% scaling, horizontal, vertical errors to 25% scaling, horizontal, vertical errors using
is changed from 0% scaling, horizontal, vertical errors to 25% scaling, horizontal, vertical errors using  step size.
step size.
Figure 12 illustrates the result of the error tolerance range. It can be observed from Figure 12 that the detection rate can reach up to 97.28%. Therefore, having this result can further prove the capability of the CoLBP features in detecting faces as well as illustrates the effect of the training dataset, which made the system insensitive to small error.

CoLBP detector performance sensitivity to different face decision criterion function parameters.
3.6. CoLBP Detector Examined on the BioID Dataset
Due to difficulties that make reproducing identical face detectors that are implemented in the literature infeasible, and in order to have a more comprehensive comparison of the CoLBP detector with the state-of-the-art detectors, the CoLBP detector is applied to the real-life BioID dataset.
BioID database [38] is recorded and distributed to be used as a benchmark for face detection and recognition experiments. BioID images are recorded to illustrate real world scenario such as the images have variation in illumination, different background, and various face sizes. The dataset consists of 1521 gray-scale frontal face images, each image has a resolution of  pixels captured for 23 different persons.
pixels captured for 23 different persons.
Following the properties of the BioID dataset, it is widely examined in the literature including, but not limited to, the following works [8, 21, 39–42]. Figure 13 shows the CoLBP detector versus the Haar-like detector for the same method of evaluation range explained in Section 3.5.

The CoLBP detector versus the Haar-like detector when examined on the BioID dataset.
It can be concluded from Figure 13 that the CoLBP detector outperforms Haar-like detector. However, same conclusion explained in Section 3.4 can be drawn on the reasons made the Haar-like detector to be more consistent with its detection results over the entire range of different face decision criterion if compared to the CoLBP detector.
Even though several papers in the literature examined the BioID dataset; however, comparing the result still a daunting problem since different methods of evaluation are used (i.e., the method that decides whether the detected region is a face or not). However, if a comparison is conducted based on the highest detection rate achieved, then the CoLBP detector achieved 98.29% detection rate using 25% scaling and transitional error while 98.27% is reported in [8] using the Improved LBP (ILBP) features and measured using the method of evaluation explained in [38], but only 1511 images were considered in [8] instead of 1521. Furthermore, it can be observed that the CoLBP detector achieves a comparable result of >95% if compared to the state-of-the-art detectors in [21, 39–42].
It can be concluded from this experiment that the CoLBP detector is not only capable to outperform the Haar-like detector on surveillance scenarios but also on the widely examined BioID dataset. Furthermore, the CoLBP detector can be regarded as not only computationally efficient but also is capable of achieving a comparative results to several state-of-the-art face detectors that are examined on the BioID dataset.
3.7. Robustness Towards Illumination and Blurring Noise
One of the properties of the examined surveillance dataset is having a decent illumination and nonblurred frames while both types of noise are common to occur in video sequences. Therefore, the CoLBP detector performance is evaluated in various artificially added illumination and blurring scenarios. In order to have a better understanding of the tolerance to noise, then  is measured
is measured

where  is the detection rate in the nonnoisy dataset, and
is the detection rate in the nonnoisy dataset, and  is the detection rate when noise is applied.
is the detection rate when noise is applied.
The  value explained in Section 2.3 was fixed for the best
value explained in Section 2.3 was fixed for the best  when CoLBP detector is examined on the surveillance sequence.
when CoLBP detector is examined on the surveillance sequence.
3.7.1. Robustness Towards Illumination
One of the powerful facts that makes the LBP features to be superior over Haar-like features is its capability to handle illumination changes [11, 21]; therefore, this experiment is conducted to examine the robustness of the proposed CoLBP features towards illumination changes. The evaluation set was brightened and dimmed by changing the contrast of the image using linear transformation in the range from  to
to  . Sample of the contrast range of the frames is shown in Figure 14.
. Sample of the contrast range of the frames is shown in Figure 14.

Visualizing the illumination range by changing the contrast of the image from  to
to  .
.
The robustness of CoLBP detector towards illumination is as illustrated in Figure 15.

CoLBP detector robustness towards illumination changes.
It can be concluded from this experiment that the CoLBP features holds the LBP features power in tolerating illumination changes. Also CoLBP features can handle a wide range of illumination changes in the range from  to
to  .
.
3.7.2. Robustness Towards Blurring
The CoLBP detector is to be used in surveillance applications; therefore, camera blurring is expected. Gaussian filters of standard deviation ( ) 1, 1.4 and 2 are applied on the evaluation dataset to add blurring noise. The blurred images using these filters look as the examples in Figure 16. The robustness towards blurring noise is tabulated in Table 3.
) 1, 1.4 and 2 are applied on the evaluation dataset to add blurring noise. The blurred images using these filters look as the examples in Figure 16. The robustness towards blurring noise is tabulated in Table 3.

Visualizing the Gaussian filter blur on the image. Original image1 pixel Gaussian blur1.4 pixel Gaussian blur2 pixel Gaussian blur
Hence it can be observed from Table 3 that the CoLBP detector has a wide range robustness towards blurring changes.
From the results presented in these experiments, several important observations can be made, and they are summarized below.
-
(i)
The CoLBP features are capable to extract face discriminative features.
-
(ii)
The co-occurrence of multiple features decreases the generalization error on the examined face dataset as well as decreases the training computational overhead in comparison to the separate features.
-
(iii)
The CoLBP features can achieve a faster face detector than other various examined LBP extensions.
-
(iv)
The CoLBP features have higher discriminative power than the Haar-like features on the examined face detection problem.
-
(v)
CoLBP features are not only computationally efficient and have higher discriminative power than Haar-like features but also achieve a comparative result to the state-of-the-art face detectors when examined on the BioID dataset.
-
(vi)
CoLBP features hold the same properties of LBP features from an aspect of tolerating wide range of illumination changes.
-
(vii)
CoLBP features are capable to handle different blurring noise.
4. Conclusion
This paper introduces an idea addressing the challenging problem of face detection in surveillance sequence where the appearing faces are usually small and the video sequence is of low-resolution. The rotational LBP features which target the pixels of the image are used. The feature extraction is performed by extracting the rotational LBP features exhaustively for all possible resolutions in the examined window to target the image structure. The CoLBP features are multiple rotational LBP features occurred simultaneously, these feature are selected using SFS algorithm. The co-occurrence of features proved the capability to increase the discriminative power of the LBP features. Experiments carried out on Ole Jensen, Viola and Jones, BioID, and real-life surveillance sequence datasets show that the proposed CoLBP features are effective in boosting face detection performance and outperform state-of-the-art face detection techniques. Experiments have also shown that CoLBP features are capable to effectively handle illumination and blurring noise. While this paper concentrates on the face detection problem, but the proven capability of the CoLBP features to extract discriminative feature with their properties to handle wide range of noise can be used for different object detection problems.
References
Hjelmås E, Low BK: Face detection: a survey. Computer Vision and Image Understanding 2001, 83(3):236-274. 10.1006/cviu.2001.0921
Yang MH, Kriegman DJ, Ahuja N: Detecting faces in images: a survey. IEEE Transactions on Pattern Analysis and Machine Intelligence 2002, 24(1):34-58. 10.1109/34.982883
Viola P, Jones M: Rapid object detection using a boosted cascade of simple features. Proceedings of IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR '01), December 2001 1: 511-518.
Schwartz WR, Gopalan R, Chellappa R, Davis LS: Robust human detection under occlusion by integrating face and person detectors. Proceedings of the 3rd International Conference on Advances in Biometrics (ICB '09), June 2009, Lecture Notes in Computer Science 5558: 970-979.
Moon H, Chellappa R, Rosenfeld A: Optimal edge-based shape detection. IEEE Transactions on Image Processing 2002, 11(11):1209-1227. 10.1109/TIP.2002.800896
Yow KC, Cipolla R: Feature-based human face detection. Image and Vision Computing 1997, 15(9):713-735. 10.1016/S0262-8856(97)00003-6
Viola P, Jones MJ: Robust real-time face detection. International Journal of Computer Vision 2004, 57(2):137-154.
Rodriguez Y: Face detection and verification using local binary patterns, Ph.D. thesis. École Polytechnique Fédérale de Lausanne, Lausanne, Switzerland; 2006.
Rowley HA, Baluja S, Kanade T: Neural network-based face detection. Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR ' 96), June 1996 203-208.
Roth D, Yang MH, Ahuja N: A SNoW-based face detector. Advances in Neural Information Processing Systems 2000, 12: 855-861.
Hadid A, Pietikäinen M, Ahonen T: A discriminative feature space for detecting and recognizing faces. Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR '04), June-July 2004, Washington, DC, USA 2: 797-804.
Cootes TF, Wheeler GV, Walker KN, Taylor CJ: View-based active appearance models. Image and Vision Computing 2002, 20(9-10):657-664. 10.1016/S0262-8856(02)00055-0
Jin H, Liu Q, Lu H, Tong X: Face detection using improved LBP under bayesian framework. Proceedings of the 3rd International Conference on Image and Graphics (ICIG '04), December 2004 306-309.
Freund Y, Schapire RE: Experiments with a new boosting algorithm. Proceedings of International Conference on Machine Learning (ICML '96), 1996 148-156.
Lienhart R, Maydt J: An extended set of Haar-like features for rapid object detection. Proceedings of the International Conference on Image Processing (ICIP'02), September 2002 1: 900-903.
Lienhart R, Kuranov A, Pisarevsky V: Empirical analysis of detection cascades of boosted classifiers for rapid object detection. Pattern Recognition, Lecture Notes in Computer Science 2003, 2781: 297-304. 10.1007/978-3-540-45243-0_39
Mita T, Kaneko T, Stenger B, Hori O: Discriminative feature co-occurrence selection for object detection. IEEE Transactions on Pattern Analysis and Machine Intelligence 2008, 30(7):1257-1269.
Mita T, Kaneko T, Hori O: Joint Haar-like features for face detection. Proceedings of the 10th IEEE International Conference on Computer Vision (ICCV '05), October 2005 1619-1626.
Tri PM: Principled asymmetric boosting approaches to rapid training and classification in face detection, Ph.D. thesis. Nanyang Technological University; 2009.
Ojala T, Pietikäinen M, Mäenpää T: Multiresolution gray-scale and rotation invariant texture classification with local binary patterns. IEEE Transactions on Pattern Analysis and Machine Intelligence 2002, 24(7):971-987. 10.1109/TPAMI.2002.1017623
Fröba B, Ernst A: Face detection with the modified census transform. Proceedings of the 6th IEEE International Conference on Automatic Face and Gesture Recognition (FGR '04), May 2004 91-96.
Zhang L, Chu R, Xiang S, Liao S, Li SZ: Face detection based on multi-block LBP representation. Advances in Biometrics, Lecture Notes in Computer Science 2007, 4642: 11-18. 10.1007/978-3-540-74549-5_2
Shen C, Paisitkriangkrai S, Zhang J: Face detection from few training examples. Proceedings of IEEE International Conference on Image Processing (ICIP '08), October 2008 2764-2767.
Friedman J, Hastie T, Tibshirani R: Additive logistic regression: a statistical view of boosting. Annals of Statistics 2000, 28(2):337-407.
Zhao S, Gao Y, Zhang B: Sobel-LBP. Proceedings of IEEE International Conference on Image Processing (ICIP '08), October 2008 2144-2147.
Heikkilä M, Pietikäinen M, Schmid C: Description of interest regions with local binary patterns. Pattern Recognition 2009, 42(3):425-436. 10.1016/j.patcog.2008.08.014
Vezhnevets A, Vezhnevets V: Modest AdaBoost-teaching AdaBoost to generalize better. Proceedings of the International Conference on the Computer Graphics and Vision (GraphiCon '05), 2005, Novosibirsk Akademgorodok, Russia 322-325.
Marill T, Green D: On the effectiveness of receptors in recognition systems. IEEE transactions on Information Theory 1963, 9(1):11-17. 10.1109/TIT.1963.1057810
Whitney AW: Direct method of nonparametric measurement selection. IEEE Transactions on Computers 1971, 20(9):1100-1103.
Stearns SD: On selecting features for pattern classifiers. Proceedings of the International Joint Conference on Pattern Recognition, 1976 71-75.
Narendra PM, Fukunaga K: A branch and bound algorithm for feature subset selection. IEEE Transactions on Computers 1977, 26(9):917-922.
Pudil P, Novovičová J, Kittler J: Floating search methods in feature selection. Pattern Recognition Letters 1994, 15(11):1119-1125. 10.1016/0167-8655(94)90127-9
Jensen OH, Larsen R: Implementing the Viola-Jones face detection algorithm, M.S. thesis. Technical University of Denmark, Denmark; 2008.
Carbonetto PS: Robust object detection using boosted learning. Department of Computer Science, University of British Columbia, Vancouver, Canada; 2002.
Louis W, Plataniotis KN: Weakly trained dual features extraction based detector for frontal face detection. Proceedings of IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP '10), March 2010, Dallas, Tex, USA 814-817.
Louis W, Plataniotis KN, Man Ro Y: Enhanced weakly trained frontal face detector for surveillance purposes. Proceedings of the 6th IEEE World Congress on Computational Intelligence (WCCI '10), July 2010, Barcelona, Spain
Popovici V, Thiran JP, Rodriguez Y, Marcel S: On performance evaluation of face detection and localization algorithms. Proceedings of the 17th International Conference on Pattern Recognition (ICPR '04), August 2004 1: 313-317.
Jesorsky O, Kirchberg KJ, Frischholz RW, et al.: Robust face detection using the hausdorff distance. Audio- and Video-Based Biometric Person Authentication, Lecture Notes in Computer Science 2001, 90-95.
Nilsson M, Nordberg J, Claesson I: Face detection using local SMQT features and split up snow classifier. Proceedings of IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP '07), April 2007 2: 589-592.
Tsao WK, Lee AJT, Liu YH, Chang TW, Lin HH: A data mining approach to face detection. Pattern Recognition 2010, 43(3):1039-1049. 10.1016/j.patcog.2009.09.005
Kirchberg KJ, Jesorsky O, Frischholz R: Genetic model optimization for Hausdorff distance-based face localization. In Proceedings of the European Conference on Computer Vision (ECCV '02), 2002. Springer; 103-111.
Shih P, Liu C: Face detection using discriminating feature analysis and support vector machine. Pattern Recognition 2006, 39(2):260-276. 10.1016/j.patcog.2005.07.003
Ojala T, Pietikäinen M, Harwood D: A comparative study of texture measures with classification based on feature distributions. Pattern Recognition 1996, 29(1):51-59. 10.1016/0031-3203(95)00067-4
Ojala T, Pietikainen M, Maenpaa T: Gray scale and rotation invariant texture classification with local binary patterns. Proceedings of the 6th European Conference on Computer Vision (ECCV '00), June-July 2000, Dublin, Ireland, Lecture Notes in Computer Science 1842: 404-420.
Paris S: Face detection toolbox. November 2009, http://www.mathworks.com/matlabcentral/fileexchange/24092-face-detection-toolbox
Acknowledgments
This work is partially funded by the Natural Sciences and Engineering Research Council of Canada (NSERC) and ORF-RE program of the Ontario Ministry of Research and Innovation through MUltimodal SurvEillance System for SECurity-RElaTed Applications (MUSES_SECRET) project. Also, MATLAB code available in [45] is used to implement some of the LBP features extensions.
Author information
Authors and Affiliations
Corresponding author
Review of Local Binary Patterns Features
Local Binary Patterns (LBP) features were first introduced in [43]. Due to their power to detect corners, edges, spots and flat ends as well as their high tolerance to illumination [20], they are used in texture classification. Simple LBP feature extraction algorithm operates by taking the value of the center pixel in a  pixels and assuming the texture of this
pixels and assuming the texture of this  matrix is the joint distribution of nine gray-scale image pixels [44]. Furthermore, it subtracts the center pixel from all surrounding pixels. The center pixel is considered as the overall luminance factor in the
matrix is the joint distribution of nine gray-scale image pixels [44]. Furthermore, it subtracts the center pixel from all surrounding pixels. The center pixel is considered as the overall luminance factor in the  matrix, and it does not provide texture information. In order to achieve scaling of gray-scale invariance and preserve the texture of the matrix, the signs of the pixels are taken. Hence,
matrix, and it does not provide texture information. In order to achieve scaling of gray-scale invariance and preserve the texture of the matrix, the signs of the pixels are taken. Hence,

where  is the LBP value for the center pixel in the
is the LBP value for the center pixel in the  matrix; the decimal value of
matrix; the decimal value of  represents the texture for this
represents the texture for this  pixel window.
pixel window.  is the gray-scale value of the surrounding pixels, and
is the gray-scale value of the surrounding pixels, and  is the gray-scale value of the center pixel.
is the gray-scale value of the center pixel.
Also,

Figure 17 shows an example of simple LBP operation. Due to this procedure, 28 possible LBP values can be obtained from  matrices.
matrices.
Figure 17
Simple LBP feature.
The LBP features are not extracted on only 1 pixel neighbor or a square window, but as in [20], they can be extracted with a circular neighbor with different radii and points. Points are considered as the number of equally spaced points that construct the LBP operator and the radius is how far the points from the central pixel lie. This LBP features type is called rotational LBP features. Rotational LBP operator is symbolized as  , where
, where  ,
,  correspond to the number of points and radius, respectively, therefore, there are
correspond to the number of points and radius, respectively, therefore, there are  possible binary words for each
possible binary words for each  . Figure 18 shows an example of LBP8,2 feature extraction.
. Figure 18 shows an example of LBP8,2 feature extraction.
Figure 18
Rotational LBP 8,2 feature extraction.
Furthermore, it was found in [20] that there is a subset of the  that spans most of the texture descriptor, this subset is called Uniform
that spans most of the texture descriptor, this subset is called Uniform  ,
,  . The Uniform
. The Uniform  words are the words that have only two flipping bits from 0 to 1 and 1 to 0 (e.g., 01110000).
words are the words that have only two flipping bits from 0 to 1 and 1 to 0 (e.g., 01110000).
Rights and permissions
Open Access This article is distributed under the terms of the Creative Commons Attribution 2.0 International License (https://creativecommons.org/licenses/by/2.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
About this article
Cite this article
Louis, W., Plataniotis, K.N. Co-Occurrence of Local Binary Patterns Features for Frontal Face Detection in Surveillance Applications. J Image Video Proc. 2011, 745487 (2011). https://doi.org/10.1155/2011/745487
Received:
Revised:
Accepted:
Published:
DOI: https://doi.org/10.1155/2011/745487