Table 7 Performance for HD, for the training ( ) and evaluation (
) and evaluation ( ) data; audio and video quality and impairment factors are derived from subjective tests (Subj.) or predicted from audio and video quality models (Pred.);
) data; audio and video quality and impairment factors are derived from subjective tests (Subj.) or predicted from audio and video quality models (Pred.); 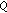 : content-blind Q-based model,
: content-blind Q-based model,  : content-aware Q-based model,
: content-aware Q-based model,  : content-blind IF-based model,
: content-blind IF-based model,  : content-aware IF-based model; in italic: the respective model performs significantly better than the corresponding basic model
: content-aware IF-based model; in italic: the respective model performs significantly better than the corresponding basic model 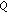 ; in bold: significantly better performing model between
; in bold: significantly better performing model between 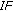 and
and 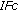 .
.
 ) and evaluation (
) and evaluation ( ) data; audio and video quality and impairment factors are derived from subjective tests (Subj.) or predicted from audio and video quality models (Pred.);
) data; audio and video quality and impairment factors are derived from subjective tests (Subj.) or predicted from audio and video quality models (Pred.); 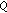 : content-blind Q-based model,
: content-blind Q-based model,  : content-aware Q-based model,
: content-aware Q-based model,  : content-blind IF-based model,
: content-blind IF-based model,  : content-aware IF-based model; in italic: the respective model performs significantly better than the corresponding basic model
: content-aware IF-based model; in italic: the respective model performs significantly better than the corresponding basic model 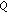 ; in bold: significantly better performing model between
; in bold: significantly better performing model between 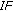 and
and 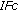 .
.Subj. |
|
|
|
|
|
|
|---|---|---|---|---|---|---|
| 0.94 | 0.68 | 0.30 | 0.94 | 0.71 | 0.28 |
| 0.94 | 0.60 | 0.21 | 0.94 | 0.64 | 0.22 |
| 0.96 | 0.53 | 0.15 | 0.95 | 0.57 | 0.14 |
| 0.98 | 0.39 | 0.07 | 0.95 | 0.58 | 0.24 |
Pred. |
|
|
|
|
|
|
| 0.91 | 0.67 | 0.26 | 0.91 | 0.71 | 0.26 |
| 0.93 | 0.63 | 0.20 | 0.92 | 0.70 | 0.25 |

















