- Research Article
- Open access
- Published:
Adaptive Edge-Oriented Shot Boundary Detection
EURASIP Journal on Image and Video Processing volume 2009, Article number: 859371 (2009)
Abstract
We study the problem of video shot boundary detection using an adaptive edge-oriented framework. Our approach is distinct in its use of multiple multilevel features in the required processing. Adaptation is provided by a careful analysis of these multilevel features, based on shot variability. We consider three levels of adaptation: at the feature extraction stage using locally-adaptive edge maps, at the video sequence level, and at the individual shot level. We show how to provide adaptive parameters for the multilevel edge-based approach, and how to determine adaptive thresholds for the shot boundaries based on the characteristics of the particular shot being indexed. The result is a fast adaptive scheme that provides a slightly better performance in terms of robustness, and a five fold efficiency improvement in shot characterization and classification. The reported work has applications beyond direct video indexing, and could be used in real-time applications, such as in dynamic monitoring and modeling of video data traffic in multimedia communications, and in real-time video surveillance. Experimental results are included.
1. Introduction
Video shot boundary detection (also called video partitioning or video segmentation) is a fundamental step in video indexing and retrieval, and in general video data management. The general objectives are to segment a given video sequence into its constituent shots, and to identify and classify the different shot transitions in the sequence. Different algorithms have been proposed, for instance, based on simple color histograms [1, 2], pixel color differences [3], color ratio histograms [4], edges [5], and motion [6–8]. In this work, we study the problem of video partitioning using an edge-based approach. Unlike ordinary colors, edges are largely invariant under local illumination changes and are much less affected by the possible motion in the video. To ensure robustness, we use both edge-based and color-based features under a multilevel decomposition framework. With the multiple decompositions, we can avoid the time-consuming problem of motion estimation by a careful choice of the decomposition level to operate at. Improvements in video partitioning have been recorded by performing a dynamic classification of the shots as the video is being analyzed, and then adaptively choosing the shot partitioning parameters based on the predicted class of the shot [9]. Automatic shot classification can also serve as an important step in approaching the elusive problem of capturing semantics or meaning in the video sequence (see, e.g., [14]).
We note that the problem of video shot partitioning (or segmentation) is not only relevant to video indexing and video data management. (See [11–14] for discussion on video query, browsing, and video object management). It is also an important issue in other areas of video communication, such as video compression and video traffic modeling [15]. In particular, for problems such as video traffic characterization and modeling, shot-level adaptation becomes mandatory, if the network is to dynamically allocate limited network resources in response to changing video data traffic.
In this work, we introduce adaptation at different stages in the video analysis process—both at the feature extraction stage and at the later stage of frame difference comparison. We propose a new method for fast shot characterization and classification required for such adaptation, using a new set of edge-based features. We introduce a method for automated threshold selection for adaptive scene partitioning schemes. In the next section, we describe recent reported work that is closely related to our approach. Section 3 presents the multilevel edge-response vectors, the basic features we propose for video partitioning. Shot characterization and adaptation in video partitioning in the context of the edge-based features is described in Section 4. Section 5 presents results on real video sequences. We conclude the paper in Section 6.
2. Related Work
The first step in content-based video data management is shot boundary detection. Simply put, it is the process of partitioning a given video sequence into its constituent shots. The purpose is to determine the beginning (and/or end) of different types of transitions that may occur in the sequence. The problem of video partitioning is compounded by the various changes that might occur in the video, (say due to illumination, motion and/or occlusion), and by the different types of shot transitions (such as fades and dissolves). The inherent variability in video shot characteristics, even for shots from the same sequence introduces further complication. The partitioning algorithm depends on the specific features used, and the similarity evaluation functions adopted. Earlier methods for video shot partitioning are described in [2–4, 16–18]. See [19–21] for a survey.
Most approaches to video partitioning make use of the color (or gray level) information in the video. The limitations of color in video partitioning are the problems of illumination variation and motion-induced false alarm. Edge based methods have thus been proposed to reduce the problem of invariance due to illumination and motion. Zabih et al. [5] made explicit use of edges in video indexing, and showed how the exiting and entering edges can be used to classify different types of shot breaks. Related methods that exploit edge information for shot detection directly in the compressed domain were proposed in [4, 18, 22, 23]. In [4] color ratio features were proposed as an alternative to color histograms, and were used to identify different types of shot changes without decompressing the video. The motivation was that color ratios capture the color boundaries or color edges in the frames. In [18, 23] methods were proposed to extract edges directly from the DCT coefficients, which can then be used for video partitioning. In [22], Abdel-Mottaleb and Krishnamachari described the edge-based information used as part of the descriptions in MPEG-7. Edge descriptors were given as 4-bin histograms, where each bin is for one of the four directions: vertical, horizontal, left-diagonal, and right-diagonal. Other related compressed domain methods are reported in [9, 13, 16].
More recent approaches to the video partitioning problem have been proposed in [9, 24–27]. Li and Lai [28] described methods for video partitioning using motion estimation, where the motion vectors are extracted using optical flow computations. To account for potential changes in the lighting conditions, the optical flow computations included a parameter to model the local illumination changes during motion estimation. Cooper et al. [25, 29] partitioning techniques that exploit possible self-similarity in the video, by classifying temporal patterns in the video sequence using kernel-based correlation. Li and Lee [26] studied video partitioning, with special emphasis on gradual transitions. Yoo et al. [27] studied both gradual and abrupt shot transitions, and proposed methods based on localized edge blocks. For abrupt shot boundaries, they proposed a correlation-based method, based on which localized edge gradients are then used for detecting gradual shot transitions.
The need for adaptation in the video indexing process was first identified in [30] (see also [9]), where they showed that video shots vary considerably from one shot to the other, even for shots that come from the same video sequence. They thus suggested that the results of an indexing scheme could be improved by treating different shots differently, for instance, by use of a different set of analysis parameters. Since then, there has been an increasing attention to the problem. In [31], detailed experiments were carried out using television news video. It was concluded that the selection of similarity thresholds was a major problem, and hence there is a need for adaptive thresholds to capture the different characteristics of broadcast news video. Vansconcelos and Lippman [10, 32] considered the duration of video shots, and showed that the shot duration can be used to predict the position of a new shot partition, and that the short duration depends critically on the video content. They used a statistical model of the shot duration to propose shot break thresholds. By classifying video shots in terms of the shot complexity and shot duration, and then performing indexing adaptively based on the video shot classes, it was shown in [9, 30] that, indeed, adaptation could be used to improve both the precision and recall simultaneously, without introducing an intolerable amount of extra computation. Dawood and Ghanbari [15] used a similar classification to model MPEG video traffic. The problem of video indexing and retrieval is very closely related to that of image indexing. Surveys on video (and/or image) indexing and retrieval can be found in [19, 21, 33, 34]. Video partitioning or segmentation has been reviewed in [20].
In this paper, we study the use of both color and edges in adaptive video partitioning. Our approach is distinct in its use of multilevel edge-based features in video partitioning, and in the provision of adaptation by a careful analysis of these multilevel features, based on the notion of shot variability. Adaptation is provided at three levels—at the feature extraction stage for the locally-adaptive edge maps, at the video sequence level, and at the individual shot level.
3. Multilevel Edge-Response Vectors
In our approach, we place emphasis on the structural information in the video, as these are generally invariant under various changes in the video, such as illumination changes, translation, and partial occlusion. Thus, in addition to the intensity values, we also make use of the edges in computing the features to be used. In particular, we use multi scale edges, since these can more easily capture localized structures in the video frames.
3.1. Multilevel Image Decomposition
Let  be an
be an  image, with
image, with  ;
;  . Given
. Given  , we decompose it into different blocks. For each block, we consider its content at different scales, and compute edge-based features at each of these scales. We then use the features to compare two adjacent frames in the video sequence. For simplicity in the discussion, we assume images are square, that is,
, we decompose it into different blocks. For each block, we consider its content at different scales, and compute edge-based features at each of these scales. We then use the features to compare two adjacent frames in the video sequence. For simplicity in the discussion, we assume images are square, that is,  . We also assume
. We also assume  , for some integer p. The ideas can easily be extended for the general rectangular image.
, for some integer p. The ideas can easily be extended for the general rectangular image.
Let b be the number of blocks at a given decomposition level. We choose k, the level of decomposition, such that  ,
,  . Let s be the scale,
. Let s be the scale,  . Then, given the original image,
. Then, given the original image,  , we can select relevant areas of the image at different scales,
, we can select relevant areas of the image at different scales,  . Let
. Let  be the sub image part selected at scale
be the sub image part selected at scale  , where
, where  . At the lowest scale (
. At the lowest scale ( ), we will have the entire image, viz:
), we will have the entire image, viz:

where  ;
;  , and
, and  ,
,  are starting positions (typically,
are starting positions (typically,  ). Let
). Let  ,
,  be the corresponding starting positions at scale
be the corresponding starting positions at scale  (these are with respect to
(these are with respect to  ,
,  in
in  ). Then we have:
). Then we have:

where,

At a given scale  , the starting positions are computed as
, the starting positions are computed as

The size of the image block selected at scale s will therefore be  , where
, where  . For a given decomposition level, we consider each of the
. For a given decomposition level, we consider each of the  -sized blocks and compute the required image features. If we fix the number of scales to 1 (i.e.,
-sized blocks and compute the required image features. If we fix the number of scales to 1 (i.e.,  ) at each level
) at each level  , (i.e., at each level, we select all the image positions within the block to compute the feature), then the multi scale scheme defaults to a simple multilevel representation of the image. Thus, using
, (i.e., at each level, we select all the image positions within the block to compute the feature), then the multi scale scheme defaults to a simple multilevel representation of the image. Thus, using  with L maximum number of levels (i.e.,
with L maximum number of levels (i.e.,  ), we will have an N-dimensional feature vector, where
), we will have an N-dimensional feature vector, where

Clearly, the number of features grows quickly with increasing  (e.g., at
(e.g., at  ,
,  ; at
; at  ,
,  ). For the multi scale representation, we have more than one scale per level. With
). For the multi scale representation, we have more than one scale per level. With  as the number of scales per level (i.e.,
as the number of scales per level (i.e.,  ), we will have
), we will have  feature values for each particular feature. In the following, we will assume a single scale (i.e.,
feature values for each particular feature. In the following, we will assume a single scale (i.e.,  , and
, and  ). Figure 1 shows schematic diagram of an image at different levels of decomposition, and a tree representation of the individual blocks from each level.
). Figure 1 shows schematic diagram of an image at different levels of decomposition, and a tree representation of the individual blocks from each level.

Multilevel decomposition (a) an image at three levels of decomposition; (b) tree representation of the decomposition.
3.2. Edge-Oriented Features
To reduce the possible effect of noise in the video, we first apply Gaussian smoothening on the input image before computing the edge-based features. Given the image  , the edge gradients are defined as
, the edge gradients are defined as  ,
,  . The gradients are obtained using appropriate edge kernels:
. The gradients are obtained using appropriate edge kernels:

where  and
and  are the horizontal and vertical gradient masks, respectively, and * represents convolution. The gradient amplitude is given by
are the horizontal and vertical gradient masks, respectively, and * represents convolution. The gradient amplitude is given by

which can be approximated using the simple absolute sum:

The phase angle is given by

These will be calculated once for each frame, but will be used at different levels of decomposition.
3.2.1. Locally Adaptive-Edge Map
The major motivation for a multilevel approach is that certain variations in an image, such as those due to edges are local in nature, and hence will be better captured by use of local (rather than global) information. For video in particular, this becomes very important. Although some variations (such as panning, tilting, and illumination) in the video could be global with respect to a particular frame, object motion and some other camera operations (such as zooming) are more easily modeled as a local phenomenon. (Note, although zooming could also be global over the video frame, the direction of the motion vectors will vary from one area of the image to the other). We capture global information by using information from the lower levels of decomposition (smaller values of k). With higher levels, we can obtain information about more localized structures in the frame. Such localized structures could be treated differently for improved performance.
We use locally adaptive thresholds to define the edge map at different decomposition levels. Each block is considered using it's own local threshold. For a given block r, at the k th level ( ), we define the edge map as follows:
), we define the edge map as follows:

where  is the corresponding gradient response in the r th block at level k, and
is the corresponding gradient response in the r th block at level k, and  is a local threshold. We can choose the threshold simply as
is a local threshold. We can choose the threshold simply as

where  is the size of the r th block at level k,
is the size of the r th block at level k,  is a constant. While the above approach to local thresholds is simple and conceptual, it however considers each block independent of the other blocks in the frame. It might be advantageous to consider the local threshold with respect to the global image variations [35]. At a given k, we can write
is a constant. While the above approach to local thresholds is simple and conceptual, it however considers each block independent of the other blocks in the frame. It might be advantageous to consider the local threshold with respect to the global image variations [35]. At a given k, we can write  since the block size would all be the same for any block, r.
since the block size would all be the same for any block, r.
Define the overall global image threshold as

where  is a constant (which can be determined empirically).
is a constant (which can be determined empirically).
The local threshold for a given block  at each level
at each level  is then given by
is then given by

where  ,
,  are, respectively, the edge response mean and standard deviation for block
are, respectively, the edge response mean and standard deviation for block  , at level
, at level  .
.
3.2.2. Edge-Based Features
At a given level  , and for each given block
, and for each given block  , we compute the following features.
, we compute the following features.
-
(i)
Color,
 ,
, 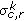 : color mean and standard deviation using
: color mean and standard deviation using  .
. -
(ii)
Edge response,
 ,
, 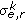 : edge response mean and standard deviation using
: edge response mean and standard deviation using  :
: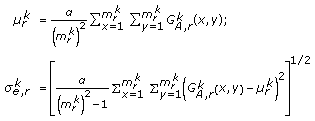 (14)
(14) -
(iii)
Phase angle,
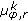 ,
, 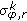 : mean phase angle and standard deviation using
: mean phase angle and standard deviation using 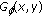 .
. -
(iv)
Edge length,
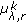 : edge length using the edge map,
: edge length using the edge map, 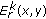 , where
, where  .
. -
(v)
Edge response at the edge points,
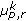 ,
,  : edge response mean and standard deviation computed only at the edge points, as defined by the edge maps.
: edge response mean and standard deviation computed only at the edge points, as defined by the edge maps.
 ,
, 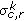 : color mean and standard deviation using
: color mean and standard deviation using  .
. ,
, 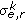 : edge response mean and standard deviation using
: edge response mean and standard deviation using  :
: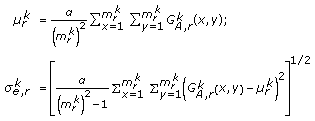
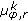 ,
, 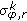 : mean phase angle and standard deviation using
: mean phase angle and standard deviation using 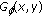 .
.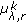 : edge length using the edge map,
: edge length using the edge map, 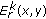 , where
, where  .
.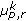 ,
,  : edge response mean and standard deviation computed only at the edge points, as defined by the edge maps.
: edge response mean and standard deviation computed only at the edge points, as defined by the edge maps.The edge points are the pixel positions that lie on the edges—as determined by the thresholds above. We call the combined features including the color features multilevel edge-response vectors (MERVs).
3.3. Similarity Evaluation Using MERVs
Having extracted the features, the next question is how to find appropriate metrics to compare two video frames using these features. Given two images  and
and  , we can compute the distance between them using the general Minkowski distance, or some other metrics. In the following we use the simple city-block distance.
, we can compute the distance between them using the general Minkowski distance, or some other metrics. In the following we use the simple city-block distance.
For the edge length, there will be no standard deviation, hence the distance will be

For the other features, we need to consider both the mean and the standard deviation. For example, for the edge response feature, we will have

Similarly, we obtain the corresponding distance  ,
,  , and
, and  for color, phase angle, and edge response at edge points, respectively. The overall distance between the two images is then determined as a simple weighted-average of the individual distances from the different features:
for color, phase angle, and edge response at edge points, respectively. The overall distance between the two images is then determined as a simple weighted-average of the individual distances from the different features:

where  .
.
The parameters  ,
,  ,
,  ,
,  ,
,  are respective weights for features based on the color, edge response, phase angle, edge length, and edge response at edge points. By simply varying the weights, we can completely ignore the contribution of any particular feature. For the weights above to be meaningful however, we need to be sure that the range of values for the individual distances will be similar. Thus, we either have to normalize all the features to the same range of values, or we can compute the distance such that the overall distance from each feature is normalized. We take the later approach, and perform normalization at the time of distance computation, based on the model-data feature pairs
are respective weights for features based on the color, edge response, phase angle, edge length, and edge response at edge points. By simply varying the weights, we can completely ignore the contribution of any particular feature. For the weights above to be meaningful however, we need to be sure that the range of values for the individual distances will be similar. Thus, we either have to normalize all the features to the same range of values, or we can compute the distance such that the overall distance from each feature is normalized. We take the later approach, and perform normalization at the time of distance computation, based on the model-data feature pairs

where again  and
and  are weights, with
are weights, with  . The normalized distances can then be used with the weights in (17) to obtain the overall distance between the frames.
. The normalized distances can then be used with the weights in (17) to obtain the overall distance between the frames.
Another important issue is the effect of each individual block in the overall difference. Let  be the weight of feature f from the r th block at level k. That is,
be the weight of feature f from the r th block at level k. That is,  , where
, where  denote respective features based on color, edge response, phase angle, edge length, and edge response at edge points. A simple approach is to adopt a method whereby for a chosen feature f, the contribution from every block at each level is given an equal weight. Effectively,
denote respective features based on color, edge response, phase angle, edge length, and edge response at edge points. A simple approach is to adopt a method whereby for a chosen feature f, the contribution from every block at each level is given an equal weight. Effectively,  , where
, where  .
.  is simply the number of blocks at the k th level. This makes the features from the lower levels of the decomposition to become more important. As the number of decomposition levels L increases, the lower-level features will dominate in the computation of the overall difference, and hence this will become very sensitive to small spatial differences in the frames. This will hence be more susceptible to noise and minute motion variations in the video. For shot classification however, this can be beneficial, since the domination of global movement or features in the video can be avoided.
is simply the number of blocks at the k th level. This makes the features from the lower levels of the decomposition to become more important. As the number of decomposition levels L increases, the lower-level features will dominate in the computation of the overall difference, and hence this will become very sensitive to small spatial differences in the frames. This will hence be more susceptible to noise and minute motion variations in the video. For shot classification however, this can be beneficial, since the domination of global movement or features in the video can be avoided.
A better approach could be to divide up the contribution to the overall difference amongst the k levels. The blocks that make up the k th level will then share the contribution allocated to that level. A simple way to do this will be by using an equal distribution of the contribution to all the levels:

In all cases, we must have  . The effect of the weights using the two cases considered above can be appreciated from Table 1.
. The effect of the weights using the two cases considered above can be appreciated from Table 1.
Considering the weights at each level, the distance between adjacent frames can be computed:

or in weighted and normalized form:

4. Adaptive Video Partitioning
When the distance  is computed for a series of adjacent video frames, the result will be a sequence of frame differences, FD-sequence for short. The actual video partitioning is performed by a further analysis of the FD-sequence. Let
is computed for a series of adjacent video frames, the result will be a sequence of frame differences, FD-sequence for short. The actual video partitioning is performed by a further analysis of the FD-sequence. Let  be the difference between two adjacent frames,
be the difference between two adjacent frames,  and
and  . The FD-sequence is defined as
. The FD-sequence is defined as  , where
, where  is the number of frames in the video. The FD-sequence is usually characterized by significant peaks at frame positions where a shot change has occurred. With the FD-sequence, the video partitioning problem then becomes that of determining appropriate thresholds to isolate these "significant peaks" from other peaks that might occur in the sequence. The shot threshold is defined as
is the number of frames in the video. The FD-sequence is usually characterized by significant peaks at frame positions where a shot change has occurred. With the FD-sequence, the video partitioning problem then becomes that of determining appropriate thresholds to isolate these "significant peaks" from other peaks that might occur in the sequence. The shot threshold is defined as  . We declare a shot partition at frame
. We declare a shot partition at frame  whenever the distance exceeds the threshold: that is, whenever
whenever the distance exceeds the threshold: that is, whenever  .
.
4.1. Adaptation at the Video Sequence Level
The description above assumes that video sequences are homogeneous, and hence can all be considered using the same set of parameters. However, video sequences vary considerably from one sequence to the other. First we consider adapting the video analysis algorithm based on the entire video sequence. That is, for each video sequence, we determine the set of analysis parameters that will produce the best results. This set of parameters is then used to analyze all the frames or shots in the video sequence.
Given the weights on the multilevel features (see (17), we can parameterize the analysis algorithm in terms of these weights,  and the threshold,
and the threshold,  . For adaptation at the sequence level, rather than considering all the features for the distance calculation, we consider only the features that are relevant to the video being analyzed. Thus, based on the particular video, we can determine the best
. For adaptation at the sequence level, rather than considering all the features for the distance calculation, we consider only the features that are relevant to the video being analyzed. Thus, based on the particular video, we can determine the best  pair for segmenting the video.
pair for segmenting the video.
To check the effect of the weights and the thresholds on different video sequences, we used a combination of the weights at different thresholds. Based on empirical analysis, we chose 32 combinations of the weights (Table 2) and 9 thresholds (Table 3).
 ).
).We observed that different videos may require different contributions from each feature (i.e., different weights,  ) for best results. Also, at a given
) for best results. Also, at a given  , different thresholds could produce different results. (See Table 6, Section 5). Similarly, for a given video sequence, various sets of weights can produce the same (best) results, but at different thresholds. Conceptually, adaptation at the sequence level should be simple. But there are several problems. First, at the sequence level, the video is still being considered at a very coarse granularity. Video shots are known to vary greatly, even for shots in the same video. Hence, different shots in the same video sequence could be very different in content. More importantly, automated mapping of the
, different thresholds could produce different results. (See Table 6, Section 5). Similarly, for a given video sequence, various sets of weights can produce the same (best) results, but at different thresholds. Conceptually, adaptation at the sequence level should be simple. But there are several problems. First, at the sequence level, the video is still being considered at a very coarse granularity. Video shots are known to vary greatly, even for shots in the same video. Hence, different shots in the same video sequence could be very different in content. More importantly, automated mapping of the  pair for each given video is a major problem, requiring a two-pass approach. This makes sequence-level adaptation unsuitable for real-time applications, or for network applications, where dynamic modeling of video data traffic is required.
pair for each given video is a major problem, requiring a two-pass approach. This makes sequence-level adaptation unsuitable for real-time applications, or for network applications, where dynamic modeling of video data traffic is required.
4.2. Shot-Level Adaptation
The above problems can be addressed by considering the individual shots that make up the video. In [9], shots were characterized based on the activity and motion in the shots, and the respective shot duration. Using the characterization, video shots were grouped into nine classes, based on which video partitioning was performed by adaptively choosing different thresholds for each shot class. In the current work, we take a different approach for the problems of video characterization and classification.
4.2.1. Estimating Video Shot Complexity
To make the thresholds sensitive to the different shot classes, we need some methods to make such thresholds locally adaptive. The overall video shot complexity depends on the activity and the motion, while the shot class depends on both the complexity and the duration of the shot. The shot duration has a strong correlation with the amount of motion in the video. The length of the shot is typically inversely proportional to the amount of motion in the video [9]. We can determine the temporal duration as we analyze the shot. We could also determine the motion complexity by computing the motion vectors using motion estimation techniques [36]. However, motion estimation is very computationally intensive.
Since we do not need accurate motion estimation to classify the shots or for adaptive indexing, an estimate of the amount of motion in the shot is enough. Thus, we can approximate the amount of motion using the differences between adjacent frames (e.g., by analyzing the FD-sequence), rather than direct computation of the motion vectors. A similar observation has been made by Tao and Orchard [37], where they noticed that the residual signal generated after motion-compensated predication is highly correlated with the gradient magnitude: the motion compensated error is larger for pixels with larger gradient magnitude on average. They thus suggested that the gradient (from one frame to the other) could be estimated from the reconstructed image using the motion estimates. In this work, we are interested in the reverse procedure; given the gradient information (as captured by the edge response vectors), we wish to estimate the amount of motion in the shot, without explicit motion estimation.
We can estimate both the image activity and the motion by using the already available multilevel edge response vectors, with appropriate weights. For example, if we use  (e.g.,
(e.g.,  , for 4 decomposition levels), or if we ignore the global averages altogether, (i.e., the contributions from level
, for 4 decomposition levels), or if we ignore the global averages altogether, (i.e., the contributions from level  ), then the lower-level features (which are increasingly localized) can be used to predict the amount of motion. We could also ignore further higher level features, for instance, levels at
), then the lower-level features (which are increasingly localized) can be used to predict the amount of motion. We could also ignore further higher level features, for instance, levels at  . We can estimate the activity by using the MERVs from just one frame in a given shot.
. We can estimate the activity by using the MERVs from just one frame in a given shot.
The motion and activity will generally result in an overall variability of the shot. The shot complexity depends directly on this shot variability. To estimate the shot variability, we use the mean and standard deviation of the frame-difference sequence (the FD-sequence) within the shot. We compute this for each of the MERV features, and use a weighted average to determine the shot variability. Given two time instants,  and
and  , (
, ( ), we compute the shot variability as follows. Let
), we compute the shot variability as follows. Let  be the duration. Let
be the duration. Let  be the frame difference sequence using a particular multilevel feature, say
be the frame difference sequence using a particular multilevel feature, say  :
:

Similarly, we compute for color, edge response, edge-response at edge points, and the phase angle. Then, as with the between-frame distances, we obtain the shot-variability using a weighted combination from all the features:

The weights here may not necessarily be the same as those used for the distances.
In [4, 9], different methods were proposed for computing the motion and image complexities, for instance, using the spectral entropy, and other metrics. With the above approach, one problem will be computing the standard deviation at each frame as the shot is progressing. This problem can be solved by doing the computations at only defined periodic intervals (the periods could also be chosen adaptively). However, one advantage of using the shot variability defined above is that the parameters required can be computed incrementally, using the preceding values. We can do this from the general definition of mean and standard deviation.
Given a data ensemble,  , and the mean of the first
, and the mean of the first  items,
items,  , we can estimate the mean when the (
, we can estimate the mean when the ( )th item is added:
)th item is added:

Similarly, for the variance (or standard deviation), we have

Solving (25) simultaneously, we obtain the incremental formula

We can use these to incrementally estimate the shot variability using the available FD-sequence. Based on the shot variability, we classify the shots into nine classes, as follows. Given  and
and  for a given shot, we classify each into three classes, namely, low (I), medium (II), and high (III), based on an equi probability classification. Let
for a given shot, we classify each into three classes, namely, low (I), medium (II), and high (III), based on an equi probability classification. Let  be the classification due to
be the classification due to  . Similarly, let
. Similarly, let  be the classification due to
be the classification due to  . Using the classifications from the two dimensions of shot variability, we define a simple mapping function
. Using the classifications from the two dimensions of shot variability, we define a simple mapping function  to determine the overall shot class, viz:
to determine the overall shot class, viz:

Table 4 shows the classification results for the test video sequence, based on the above scheme.
4.2.2. Adaptive Shot Thresholds
Having characterized and classified the shots based on the shot variability, the next question is to determine the parameters for video shot partitioning for a given shot. Ideally, given the FD sequence, (and assuming that it was obtained from a distance (and not a similarity) measure), we expect that the threshold for shot changes should decrease with increasing shot length, but increase with increasing shot complexity (or variability). Formally, given a video shot  , we classify it into a certain shot class,
, we classify it into a certain shot class,  . The problem of shot-level adaptation then is to determine the parameter set (i.e., the
. The problem of shot-level adaptation then is to determine the parameter set (i.e., the  pair) that will produce the best results for all shots,
pair) that will produce the best results for all shots,  ,
,  . Here, best results are defined in terms of information retrieval measures of precision and recall.
. Here, best results are defined in terms of information retrieval measures of precision and recall.
We take a pragmatic approach to the problem of determining the parameters. Using a training set of video shots, we use a simple clustering technique to determine the  pairs that produce the best results for each shot class in the training set. We then use these pairs for analysis of the test video sequences.
pairs that produce the best results for each shot class in the training set. We then use these pairs for analysis of the test video sequences.
Let  be the weight-threshold pair that defines the parameter set for video segmentation. Let
be the weight-threshold pair that defines the parameter set for video segmentation. Let  be the number of video sequences used for the training set. We use the edge-response vectors to analyze the video shots in the training set, using all the available weights and thresholds (i.e., 32 weights and 9 thresholds in all, see Tables 2 and 3. Let
be the number of video sequences used for the training set. We use the edge-response vectors to analyze the video shots in the training set, using all the available weights and thresholds (i.e., 32 weights and 9 thresholds in all, see Tables 2 and 3. Let  denote the set of
denote the set of  pairs that produced correct partitioning results for the class
pairs that produced correct partitioning results for the class  shots in video sequence
shots in video sequence  . To select the best
. To select the best  pair for a given shot class,
pair for a given shot class,  , all we need is the intersection of
, all we need is the intersection of  , for all the
, for all the  sequences:
sequences:

When we have  , then any member of
, then any member of  can be used as the best parameter set. The major problem is when
can be used as the best parameter set. The major problem is when  , that is, the intersection is empty, implying that no single parameter set always produced correct results for all the class
, that is, the intersection is empty, implying that no single parameter set always produced correct results for all the class  shots in the training sequences. Two approaches can be used to address this problem.
shots in the training sequences. Two approaches can be used to address this problem.
For each shot in a given video sequence, we define an array  ,
,  ,
,  , such that
, such that  if the shot is correctly partitioned with the parameter set
if the shot is correctly partitioned with the parameter set  pair, and
pair, and  otherwise. We use
otherwise. We use  ,
,  in our implementation. Let
in our implementation. Let  denote the cumulative value in the
denote the cumulative value in the  arrays for all the class
arrays for all the class  shots in video sequence
shots in video sequence  . Then, the best parameter set for the class c shots is determined as
. Then, the best parameter set for the class c shots is determined as

where,  .
.
The above selects the parameter set that produced the best overall result, over all the shots of a given class in the training set. This could be dominated by one video sequence that has many shots of the given type. A variation could be to use the parameter set that produced the best result over the shots of a given class from most of the sequences, although it may not necessarily produce the best results over all shots. Thus,

where,  .
.
5. Results
To test the performance of the proposed edge-based adaptive method, we ran some experiments using two sets of video sequences. The first set had 6 sequences taken from standard MPEG-7 sequences, and from available online video sources [31]. For each video sequence, the frame size was fixed at  . The second set had 5 sequences taken from the US National Institute of Standards (NIST) benchmark TRECVID 2001 test sequences. The frame size for sequences in this set was
. The second set had 5 sequences taken from the US National Institute of Standards (NIST) benchmark TRECVID 2001 test sequences. The frame size for sequences in this set was  . The experiments were carried out in a MATLAB Version 7.3.0.267 (R2006b) environment using a personal computer with Intel(R) CPU T2400, running at 1.83 GHz with 1.99 GB RAM. We measure performance in terms of the information retrieval measures of precision and recall. We use the following notation:
. The experiments were carried out in a MATLAB Version 7.3.0.267 (R2006b) environment using a personal computer with Intel(R) CPU T2400, running at 1.83 GHz with 1.99 GB RAM. We measure performance in terms of the information retrieval measures of precision and recall. We use the following notation:  set of all positions of true scene cuts in a test video sequence,
set of all positions of true scene cuts in a test video sequence,  set of all positions of scene cuts returned by the system,
set of all positions of scene cuts returned by the system,  subset of
subset of  that are true scene cuts (i.e., correct detection, or
that are true scene cuts (i.e., correct detection, or  ). Then, precision
). Then, precision  , and recall
, and recall  .
.
5.1. Effectiveness of MERVs on Non-Adaptive Partitioning
First, we tested the effectiveness of the proposed edge-response vectors in video partitioning, without consideration for adaptation. This is important, since the results of the adaptive schemes will also be influenced by the inherent robustness of the edge-based features. The results are shown in Table 5. As can be seen, the edge-oriented approach produced about 90% in terms of precision and recall.
5.2. Adaptive Partitioning
Table 6 shows the results for adaptation at the video sequence level. The last two columns show the weight-threshold parameter pairs that were used to produce the indicated results. Where there are more than two entries, it means that the indicated entries all produced the same result. The table shows a significant improvement over the non-adaptive approach. The sequence-level adaptation is a two-pass method. That is, it needs a first pass on the data to determine the analysis parameters, and a second pass to perform the analysis. For some applications, such as real-time video streaming, the two-pass approach may not be applicable. Shot-level adaptation avoids the two-pass problem. Table 7 shows that results for shot-level adaptation, based on shot characterization and classification using the proposed shot variability measure. The results are a little worse than the two-pass method using sequence-level adaptation, but generally better than the static approach.
5.3. Comparative Results
We performed a comparative experiment using other popular techniques. Table 8 shows the results. For color histograms, we used region-based histograms with 16 blocks ( regions) per frame, where
regions) per frame, where  and
and  are the frame dimensions. Analysis using motion-vector-based methods [28] are based on
are the frame dimensions. Analysis using motion-vector-based methods [28] are based on  sub blocks. The specific kernel size used for Cooper et al.'s DCT-based method [25] are also indicated in the table, as this varied significantly from sequence to sequence. In all cases, we have reported results using the parameters that gave the best overall result for a given video sequence, or for the test video set used. Apart from the results in [9], none of the other methods used adaptive partitioning. Thus, we can compare the performance of the static (non-adaptive) method using the proposed MERVs as features with the results from the other schemes. The table shows that MERV features are very competitive, having a comparable performance with the correlation-based method [27], the best performing technique of the other schemes tested. While simple color histogram did well on some video sequences, it produced poor performance on CROPS and CANYON video sets. This is mainly because these two sequences have both indoor and outdoor scenes involving significant variation in illumination. Obviously color features are easily affected by this variation, and hence the precision of the color-histogram based method was quite low for these sequences. The same explains the poor performance of the motion-vector-based method. Illumination variation between frames often leads to poor motion detection and thus a significant error in the motion vectors (even with the special parameter for illumination handling used in [28]). Overall, the results from the adaptive schemes are generally better than those from the non-adaptive schemes. This can be explained by the fact that the adaptive schemes spend time to analyze each shot first, before deciding on the analysis parameters. Thus, they are able to adapt better to the changing nature of shot characteristics as we move along in the video sequence.
sub blocks. The specific kernel size used for Cooper et al.'s DCT-based method [25] are also indicated in the table, as this varied significantly from sequence to sequence. In all cases, we have reported results using the parameters that gave the best overall result for a given video sequence, or for the test video set used. Apart from the results in [9], none of the other methods used adaptive partitioning. Thus, we can compare the performance of the static (non-adaptive) method using the proposed MERVs as features with the results from the other schemes. The table shows that MERV features are very competitive, having a comparable performance with the correlation-based method [27], the best performing technique of the other schemes tested. While simple color histogram did well on some video sequences, it produced poor performance on CROPS and CANYON video sets. This is mainly because these two sequences have both indoor and outdoor scenes involving significant variation in illumination. Obviously color features are easily affected by this variation, and hence the precision of the color-histogram based method was quite low for these sequences. The same explains the poor performance of the motion-vector-based method. Illumination variation between frames often leads to poor motion detection and thus a significant error in the motion vectors (even with the special parameter for illumination handling used in [28]). Overall, the results from the adaptive schemes are generally better than those from the non-adaptive schemes. This can be explained by the fact that the adaptive schemes spend time to analyze each shot first, before deciding on the analysis parameters. Thus, they are able to adapt better to the changing nature of shot characteristics as we move along in the video sequence.
We then tested the methods on another set of video sequences, this time using five sequences from the NIST benchmark TRECVID 2001 video sequences. The sequences and annotations by NIST, such as positions of true scene cuts are available via the NIST TRECVID website (http://www-nlpir.nist.gov/projects/trecvid/revised.html). (We could not get access to more recent sequences used in the TRECVID series. The most recent versions are available only for competitors in the TRECVID challenge. All the same, we believe that the 2001 data still provides another independent data set suitable for testing the algorithms). The results on the TRECVID sequences are shown in Table 9. The overall result is not too different from those of Table 8. Both the proposed method and the correlation method produced better results than the others. Both had about the same average recall, with the proposed method performing slightly better in recall (0.922 versus 0.906).
We also compared the proposed adaptive scheme with the scene-adaptive method proposed in [9]. The major difference was in terms of scene characterization. After characterization, we then used the same MERV features to perform video partitioning. Thus, this essentially compares the performance of the proposed shot variability measure for video shot characterization and classification against that of characterization using explicit motion and activity. Using shot variability for shot characterization and classification is slightly superior to using motion and activity complexity measures [9], with (precision, recall) values of (0.96, 0.93) versus (0.94, 0.91). A more striking difference, however, can be observed by considering the computational requirements for the two approaches. Using shot variability as a shot complexity measure is about 5 times faster than using motion and activity. The shot variability measure does not involve explicit motion estimation and activity characterization, but rather uses the same features (i.e., the FD-sequence) that were used in the analysis. Thus, it is generally more efficient than using motion and activity. Table 10 shows the overall time taken by the different methods in video partitioning. The reported time represents the average feature extraction time per frame required in analyzing a given video sequence.
6. Discussion and Conclusion
Although video partitioning is an actively researched area, recent publications [9, 20, 24–28] show that the problem is far from being completely resolved. The major contributions of this paper are on two aspects of the video partitioning problem. The first is the proposed new set of features (the multilevel edge response vectors (MERVs) for video partitioning. The edge-based nature of the features makes them particularly suitable in handling significant illumination variations in the video, while the multilevel decomposition framework makes it possible to adapt the features to the nature of the video frames being considered. The second contribution is on adaptive video partitioning. While adaptive video partitioning was first described in [9, 30], here we propose a new and more efficient method for performing the scene characterization required for scene partitioning, and a method for automated determination of thresholds based on the video shot classes. The proposed method is online—performing scene characterization and classification as the frames in a given shot are being observed, rather than waiting until the end of a given shot (as was done in [9]). This feature, coupled with the improved efficiency in shot characterization makes the approach particularly suitable for fast and online characterization of the video, which is important in both video retrieval, and in video traffic modeling for adaptive network resource allocation [15]. We mention that, while we have provided adaptation based on the MERV features proposed, the general idea of adaptation in video analysis is independent of the specific features being used. For any given feature, the idea of adaptation can be applied by a careful study of the feature in question, and then adapting the analysis parameters using this feature based on the nature of the shot being analyzed.
In conclusion, we have studied the problem of video segmentation, using an adaptive edge-oriented framework. Adaptation is provided by an analysis of the video shot characteristics using the frame difference sequence. In particular, we defined the shot variability measure, based on which the video shots are characterized and then classified. To provide adaptation in the analysis, we determine the best set of parameters for each given shot class, and then analyze the shots that belong to the given class using only these parameter sets. An algorithm for determining the best parameters for each given shot class is presented. We described adaptation at three levels: at the feature extraction stage for the locally-adaptive edge maps, at the video sequence level, and at the individual shot level.
Experimental results show that the proposed multilevel edge-based features provide a performance of about 90% in terms of average precision and recall. In comparison with traditional approaches, the adaptive schemes provide a better performance over non-adaptive approaches, using the same multilevel edge-based features—with video sequence level adaptation producing about 99% performance. Further, the use of shot variability as a measure of shot complexity resulted in a slightly superior performance (about 2% improvement in precision) over a previously proposed method of explicit motion estimation and shot activity analysis. However, in terms of efficiency, using the shot variability led to a five fold improvement in efficiency. The reported work has applications beyond video indexing and retrieval. In particular, given the significant reduction in computations, the approach becomes attractive for real-time applications, such as in dynamic monitoring, characterization and modeling of video data traffic, and in real-time video surveillance.
References
Swain MJ, Ballard DH: Color indexing. International Journal of Computer Vision 1991,7(1):11-32. 10.1007/BF00130487
Nagasaka A, Tanaka Y: Automatic video indexing and full-video search for object appearances. In Visual Database Systems II. Edited by: Knuth E, Wegner LM. Elsevier; 1992:113-127.
Zhang H, Kankanhalli A, Smoliar SW: Automatic partitioning of full-motion video. Multimedia Systems 1993,1(1):10-28. 10.1007/BF01210504
Adjeroh DA, Lee MC: Robust and efficient transform domain video sequence analysis: an approach from the generalized color ratio model. Journal of Visual Communication and Image Representation 1997,8(2):182-207. 10.1006/jvci.1997.0349
Zabih R, Miller J, Mai K: A feature-based algorithm for detecting and classifying production effects. Multimedia Systems 1999,7(2):119-128. 10.1007/s005300050115
Courtney JD: Automatic video indexing via object motion analysis. Pattern Recognition 1997,30(4):607-625. 10.1016/S0031-3203(96)00107-0
Bouthemy P, Gelgon M, Ganansia F: A unified approach to shot change detection and camera motion characterization. IEEE Transactions on Circuits and Systems for Video Technology 1999,9(7):1030-1044. 10.1109/76.795057
Dagtas S, Al-Khatib W, Ghafoor A, Kashyap RL: Models for motion-based video indexing and retrieval. IEEE Transactions on Image Processing 2000,9(1):88-101. 10.1109/83.817601
Adjeroh DA, Lee MC: Scene-adaptive transform domain video partitioning. IEEE Transactions on Multimedia 2004,6(1):58-69. 10.1109/TMM.2003.819578
Vasconcelos N, Lippman A: Statistical models of video structure for content analysis and characterization. IEEE Transactions on Image Processing 2000,9(1):3-19. 10.1109/83.817595
Subrahmanian VS: Principles of Multimedia Database Systems. Morgan Kaufmann, San Mateo, Calif, USA; 1998.
Kuo TCT, Chen ALP: Content-based query processing for video databases. IEEE Transactions on Multimedia 2000,2(1):1-13. 10.1109/6046.825790
Taskiran C, Chen J-Y, Albiol A, Torres L, Bouman CA, Delp EJ: ViBE: a compressed video database structured for active browsing and search. IEEE Transactions on Multimedia 2004,6(1):103-118. 10.1109/TMM.2003.819783
Cheung S-CS, Zakhor A: Fast similarity search and clustering of video sequences on the world-wide-web. IEEE Transactions on Multimedia 2005,7(3):524-537.
Dawood AHM, Ghanbari M: Content-based MPEG video traffic modeling. IEEE Transactions on Multimedia 1999,1(1):77-87. 10.1109/6046.748173
Arman F, Hsu A, Chiu M-Y: Image processing on encoded video sequences. Multimedia Systems 1994,1(5):211-219. 10.1007/BF01268945
Hampapur A, Jain R, Weymouth TE: Production model based digital video segmentation. Multimedia Tools and Applications 1995,1(1):9-46. 10.1007/BF01261224
Lee S-W, Kim Y-M, Choi SW: Fast scene change detection using direct feature extraction from MPEG compressed videos. IEEE Transactions on Multimedia 2000,2(4):240-254. 10.1109/6046.890059
Ahanger G, Little TDC: A survey of technologies for parsing and indexing digital video. Journal of Visual Communication and Image Representation 1996,7(1):28-43. 10.1006/jvci.1996.0004
Hanjalic A: Shot-boundary detection: unraveled and resolved? IEEE Transactions on Circuits and Systems for Video Technology 2002,12(2):90-105. 10.1109/76.988656
Mandal MK, Idris F, Panchanathan S: A critical evaluation of image and video indexing techniques in the compressed domain. Image and Vision Computing 1999,17(7):513-529. 10.1016/S0262-8856(98)00143-7
Abdel-Mottaleb M, Krishnamachari S: Multimedia descriptions based on MPEG-7: extraction and applications. IEEE Transactions on Multimedia 2004,6(3):459-468. 10.1109/TMM.2004.827500
Shen B, Sethi IK: Direct feature extraction from compressed images. Storage and Retrieval for Still Image and Video Databases IV, February 1996, San Jose, Calif, USA, Proceedings of SPIE 2670: 404-414.
Bescos J, Cisneros G, Martinez JM, Menendez JM, Cabrera J: A unified model for techniques on video-shot transition detection. IEEE Transactions on Multimedia 2005,7(2):293-307.
Cooper M, Liu T, Rieffel E: Video segmentation via temporal pattern classification. IEEE Transactions on Multimedia 2007,9(3):610-618.
Li S, Lee M-C: Effective detection of various wipe transitions. IEEE Transactions on Circuits and Systems for Video Technology 2007,17(6):663-673.
Yoo H-W, Ryoo H-J, Jang D-S: Gradual shot boundary detection using localized edge blocks. Multimedia Tools and Applications 2006,28(3):283-300. 10.1007/s11042-006-7715-8
Li W-K, Lai S-H: Integrated video shot segmentation algorithm. In Storage and Retrieval for Media Databases 2003, January 2003, Santa Clara, Calif, USA, Proceedings of SPIE Edited by: Yeung MM, Lienhart RW, Li C-S. 5021: 264-271.
Cooper M, Foote J, Adcock J, Casi S: Shot boundary detection via similarity analysis. Proceedings of the TRECVID Workshop, November 2003
Adjeroh DA, Lee MC: Adaptive transform domain video shot analysis. Proceedings of IEEE International Conference on Multimedia Computing and Systems, June 1997, Ontario, Canada
O'Toole C, Smeaton A, Murphy N, Marlow S: Evaluation of automatic shot boundary detection on a large video test suite. Proceedings of Conference on Challenge of Image Retrieval, February 1999, Newcastle Upon Tyne, UK
Vasconcelos N, Lippman A: A Bayesian video modeling framework for shot segmentation and content characterization. Proceedings of Workshop on Content-Based Access to Image and Video Libraries, 1997, San Juan, Puerto Rico, USA
Rui Y, Huang TS, Chang S-F: Image retrieval: current techniques, promising directions, and open issues. Journal of Visual Communication and Image Representation 1999,10(1):39-62. 10.1006/jvci.1999.0413
Smeulders AWM, Worring M, Santini S, Gupta A, Jain R: Content-based image retrieval at the end of the early years. IEEE Transactions on Pattern Analysis and Machine Intelligence 2000,22(12):1349-1380. 10.1109/34.895972
Al-Fahoum AS, Reza AM: Combined edge crispiness and statistical differencing for deblocking JPEG compressed images. IEEE Transactions on Image Processing 2001,10(9):1288-1298. 10.1109/83.941853
Dufaux F, Moscheni F: Motion estimation techniques for digital TV: a review and a new contribution. Proceedings of the IEEE 1995,83(6):858-876. 10.1109/5.387089
Tao B, Orchard MT: Gradient-based residual variance modeling and its applications to motion-compensated video coding. IEEE Transactions on Image Processing 2001,10(1):24-35. 10.1109/83.892440
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
Open Access This article is distributed under the terms of the Creative Commons Attribution 2.0 International License (https://creativecommons.org/licenses/by/2.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
About this article
Cite this article
Adjeroh, D., Lee, M.C., Banda, N. et al. Adaptive Edge-Oriented Shot Boundary Detection. J Image Video Proc 2009, 859371 (2009). https://doi.org/10.1155/2009/859371
Received:
Revised:
Accepted:
Published:
DOI: https://doi.org/10.1155/2009/859371