- Research Article
- Open access
- Published:
From 2D Silhouettes to 3D Object Retrieval: Contributions and Benchmarking
EURASIP Journal on Image and Video Processing volume 2010, Article number: 367181 (2010)
Abstract
3D retrieval has recently emerged as an important boost for 2D search techniques. This is mainly due to its several complementary aspects, for instance, enriching views in 2D image datasets, overcoming occlusion and serving in many real-world applications such as photography, art, archeology, and geolocalization. In this paper, we introduce a complete "2D photography to 3D object" retrieval framework. Given a (collection of) picture(s) or sketch(es) of the same scene or object, the method allows us to retrieve the underlying similar objects in a database of 3D models. The contribution of our method includes (i) a generative approach for alignment able to find canonical views consistently through scenes/objects and (ii) the application of an efficient but effective matching method used for ranking. The results are reported through the Princeton Shape Benchmark and the Shrec benchmarking consortium evaluated/compared by a third party. In the two gallery sets, our framework achieves very encouraging performance and outperforms the other runs.
1. Introduction
3D object recognition and retrieval recently gained a big interest [27] because of the limitation of the "2D-to-2D" approaches. The latter suffer from several drawbacks such as the lack of information (due for instance to occlusion), pose sensitivity, illumination changes, and so forth. This is also due to the exponential growth of storage and bandwidth on Internet, the increasing needs for services from 3D content providers (museum institutions, car manufacturers, etc.), and the easiness in collecting gallery sets1. Furthermore, computers are now equipped with highly performant, easy to use, 3D scanners and graphic facilities for real-time modeling, rendering, and manipulation. Nevertheless, at the current time, functionalities including retrieval of 3D models are not yet sufficiently precise in order to be available for large usage.
Almost all the 3D retrieval techniques are resource (time and memory) demanding prior to achieve recognition and ranking. They usually operate on massive amount of data and require many upstream steps including object alignment, 3D-to-2D projections and normalization. However and when no hard runtime constraints are expected, 3D search engines offer real alternatives and substantial gains in performance, with respect to (only) image-based retrieval approaches; mainly when the relevant informations are appropriately extracted and processed (see, e.g., [8]).
Existing 3D object retrieval approaches can either be categorized into those operating directly on the 3D content and those which extract "2.5D" or 2D contents (stereo-pairs or multiple views of images, artificially rendered 3D objects, silhouettes, etc.). Comprehensive surveys on 3D retrieval can be found in [6, 8, 9, 34, 35, 41]. Existing state of the art techniques may also be categorized depending on the fact that they require a preliminary step of alignment or operate directly by extracting global invariant 3D signatures such as Zernike's 3D moments [28]. The latter are extracted using salient characteristics on 3D, "2.5D," or 2D shapes and ranked according to similarity measures. Structure-based approaches, presented in [19, 36, 37, 43], encode topological shape structures and make it possible to compute efficiently, without pose alignment, similarity between two global or partial 3D models. Authors in [7, 18] introduced two methods for partial shape-matching able to recognize similar subparts of objects represented as 3D polygonal meshes. The methods in [17, 23, 33] use spherical harmonics in order to describe shapes, where rotation invariance is achieved by taking only the power spectrum of the harmonic representations and discarding all "rotation-dependent" informations. Other approaches include those which analyze 3D objects using analytical functions/transforms [24, 42] and also those based on learning [29].
Another family of 3D object retrieval approaches belongs to the frontier between 2D and 3D querying paradigms. For instance, the method in [32] is based on extracting and combining spherical 3D harmonics with "2.5D" depth informations and the one in [15, 26] is based on selecting characteristic views and encoding them using the curvature scale space descriptor. Other "2.5D" approaches [11] are based on extracting rendered depth lines (as in [10, 30, 39]), resulting from vertices of regular dodecahedrons and matching them using dynamic programming. Authors in [12–14] proposed a 2D method based on Zernike's moments that provides the best results on the Princeton Shape Benchmark [34]. In this method, rotation invariance is obtained using the light-field technique where all the possible permutations of several dodecahedrons are used in order to cover the space of viewpoints around an object.
1.1. Motivations
Due to the compactness of global 3D object descriptors, their performance in capturing the inter/intraclass variabilities are known to be poor in practice [34]. In contrast, local geometric descriptors, even though computationally expensive, achieve relatively good performance and capture inter/intraclass variabilities (including deformations) better than global ones (see Section 5). The framework presented in this paper is based on local features and also cares about computational issues while keeping advantages in terms of precision and robustness.
Our target is searching 3D databases of objects using one or multiple 2D views; this scheme will be referred to as "2D-to-3D". We define our probe set as a collection of single or multiple views of the same scene or object (see Figure 2) while ourgallery set corresponds to a large set of 3D models. A query, in the probe set, will either be (i) multiple pictures of the same object, for instance stereo-pair, user's sketches, or (ii) a 3D object model processed in order to extract several views; so ending with the "2D-to-3D" querying paradigm in both cases (i) and (ii). Gallery data are also processed in order to extract several views for each 3D object (see Section 2).
At least two reasons motivate the use of the "2D-to-3D" querying paradigm:
-
(i)
The difficulty of getting "3D query models" when only multiple views of an object of interest are available (see Figure 2). This might happen when 3D reconstruction techniques [21] fail or when 3D acquisition systems are not available. "2D-to-3D" approaches should then be applied instead.
-
(ii)
3D gallery models can be manipulated via different similarity and affine transformations, in order to generate multiple views which fit the 2D probe data, so "2D-to-3D" matching and retrieval can be achieved.
1.2. Contributions
This paper is a novel "2D-to-3D" retrieval framework with the following contributions.
-
(i)
A new generative approach is proposed in order to align andnormalize the pose of 3D objects and extract their 2D canonical views. The method is based on combining three alignments (identity and two variants of principal component analysis (PCA)) with the minimal visual hull (see Figure 1 and Section 2). Given a 3D object, this normalization is achieved by minimizing its visual hull with respect to different pose parameters (translation, scale, etc.). We found in practice that this clearly outperforms the usual PCA alignment (see Figure 10 and Table 2) and makes the retrieval process invariant to several transformations including rotation, reflection, translation, and scaling.
-
(ii)
Afterwards, robust and compact contour signatures are extracted using the set of 2D canonical views. Our signature is an implementation of the multiscale curve representation first introduced in [2]. It is based on computing convexity/concavity coefficients on the contours of the (2D) object views. We also introduce a global descriptor which captures the distributions of these coefficients in order to perform pruning and speed up the whole search process (see Figures 3 and 12).
-
(iii)
Finally, ranking is performed using our variant of dynamic programming which considers only a subset of possible matches thereby providing a considerable gain in performance for the same amount of errors (see Figure 12).

"Gallery Set Processing." This figure shows the alignment process on one 3D object of the gallery set. First, we compute the smallest enclosing ball of this 3D object, then we combine PCA with the minimal visual-hull criterion in order to align the underlying 3D model. Finally, we extract three silhouettes corresponding to three canonical views.

"Probe Set Processing." In the remainder of this paper, queries are considered as one or multiview silhouettes taken from different sources either (i) collections of multiview pictures, (ii) 3D models, or (iii) hand-drawn sketches (see experiments in Section 5).

This figure shows an overview of the matching framework. First, we compute distances between the global signature of the query and all objects in the database. According to these distances, we create a ranked list. Then, we search the best matching between the local signatures of the query and the top k ranked objects.
Figures 1, 2, and 3 show our whole proposed matching, querying, and retrieval framework which was benchmarked through the Princeton Shape Benchmark [34] and the international Shrec'09 contest on structural shape retrieval [1]. This framework achieves very encouraging performance and outperforms almost all the participating runs.
In the remainder of this paper, we consider the following terminology and notation. A probe (query) data is again defined either as (i) a 3D object model (denoted  or
or  ) processed in order to extract multiple 2D silhouettes, (ii) multiple sketched contours of the same mental query (target), or (iii) simply 2D silhouettes extracted from multiple photos of the same category (see Figure 2). Even though these acquisition scenarios are different, they allcommonly end up by providing multiple silhouettes describing the user's intention.
) processed in order to extract multiple 2D silhouettes, (ii) multiple sketched contours of the same mental query (target), or (iii) simply 2D silhouettes extracted from multiple photos of the same category (see Figure 2). Even though these acquisition scenarios are different, they allcommonly end up by providing multiple silhouettes describing the user's intention.
Let  be a random variable standing for the 3D coordinates of vertices in any 3D model. For a given object, we assume that
be a random variable standing for the 3D coordinates of vertices in any 3D model. For a given object, we assume that  is drawn from an existing but unknown probability distribution
is drawn from an existing but unknown probability distribution  . Let us consider
. Let us consider  as
as  realizations of
realizations of  , forming a 3D object model.
, forming a 3D object model.  or
or  will be used in order to denote a 3D model belonging to the gallery set while
will be used in order to denote a 3D model belonging to the gallery set while  is a generic 3D object either belonging to the gallery or the probe set. Without any loss of generality 3D models are characterized by a set of vertices which may be meshed in order to form a closed surface or compact manifold of intrinsic dimension two. Other notations and terminologies will be introduced as we go through different sections of this paper which is organized as follows. Section 2 introduces the alignment and pose normalization process. Section 3 presents the global and the local multiscale contour convexity/concavity signatures. The matching process together with pruning strategies are introduced in Section 4, ending with experiments and comparison on the Princeton Shape Benchmark and the very recent Shrec'09 international benchmark in Section 5.
is a generic 3D object either belonging to the gallery or the probe set. Without any loss of generality 3D models are characterized by a set of vertices which may be meshed in order to form a closed surface or compact manifold of intrinsic dimension two. Other notations and terminologies will be introduced as we go through different sections of this paper which is organized as follows. Section 2 introduces the alignment and pose normalization process. Section 3 presents the global and the local multiscale contour convexity/concavity signatures. The matching process together with pruning strategies are introduced in Section 4, ending with experiments and comparison on the Princeton Shape Benchmark and the very recent Shrec'09 international benchmark in Section 5.
2. Pose Estimation
The goal of this step is to make retrieval invariant to 3D transformations (including scaling, translation, rotation, and reflection) and also to generate multiple views of 3D models in the gallery (and possibly the probe2) sets. Pose estimation consists in finding the parameters of the above transformations (denoted resp.  ,
,  ,
,  and
and  ) by normalizing 3D models in order to fit into canonical poses. The underlying orthogonal 2D views will be referred to as the canonical views (see Figure 1).
) by normalizing 3D models in order to fit into canonical poses. The underlying orthogonal 2D views will be referred to as the canonical views (see Figure 1).
Our alignment process is partly motivated by advances in cognitive psychology of human perception (see, e.g., [25]). These studies have shown that humans recognize shapes by memorizing specific views of the underlying 3D real-world objects. Following these statements, we introduce a new alignment process which mimics and finds specific views (also referred to as canonical views). Our approach is based on the minimization of a visual-hull criterion defined as the area surrounded by silhouettes extracted from different object views.
Let us consider  and given a 3D object
and given a 3D object  , our normalization process is generative, that is, based on varying and finding the optimal set of parameters
, our normalization process is generative, that is, based on varying and finding the optimal set of parameters

here  denotes the global normalization transformation resulting from the combination of translation, rotation, scaling, and reflection.
denotes the global normalization transformation resulting from the combination of translation, rotation, scaling, and reflection.  ,
,  , denote, respectively, the "3D-to-2D" parallel projections on the
, denote, respectively, the "3D-to-2D" parallel projections on the  ,
,  , and
, and  canonical 2D planes. These canonical planes are, respectively, characterized by their normals
canonical 2D planes. These canonical planes are, respectively, characterized by their normals  ,
,  , and
, and  . The visual hull in (1) is defined as the sum of the projection areas of
. The visual hull in (1) is defined as the sum of the projection areas of using
using . Let
. Let  ,
,  , here
, here  provides this area on each 2D canonical plane.
provides this area on each 2D canonical plane.
The objective function (1) considers that multiple 3D instances of the same "category" are aligned (or have the same pose), if the optimal transformations (i.e.,  ), applied on the large surfaces of these 3D instances, minimize their areas. This makes the normals of these principal surfaces either orthogonal or collinear to the camera axis. Therefore, the underlying orthogonal views correspond indeed to the canonical views3 (see Figures 1 and 4) as also supported in experiments (see Figure 10 and Table 2).
), applied on the large surfaces of these 3D instances, minimize their areas. This makes the normals of these principal surfaces either orthogonal or collinear to the camera axis. Therefore, the underlying orthogonal views correspond indeed to the canonical views3 (see Figures 1 and 4) as also supported in experiments (see Figure 10 and Table 2).

This figure shows examples of alignments with our proposed methods.
It is clear that the objective function (1) is difficult to solve as one needs to recompute, for each possible  the underlying visual hull. So it becomes clear that parsing the domain of variation of
the underlying visual hull. So it becomes clear that parsing the domain of variation of  makes the search process tremendous. Furthermore, no gradient descent can be achieved, as there is no guarantee that
makes the search process tremendous. Furthermore, no gradient descent can be achieved, as there is no guarantee that  is continuous w.r.t.,
is continuous w.r.t.,  . Instead, we restrict the search by considering few possibilities; in order to define the optimal pose of a given object
. Instead, we restrict the search by considering few possibilities; in order to define the optimal pose of a given object  , the alignment, which locally minimizes the visual-hull criterion (1), is taken as one of the three possible alignments obtained according to the following procedure.
, the alignment, which locally minimizes the visual-hull criterion (1), is taken as one of the three possible alignments obtained according to the following procedure.
Translation and Scaling
 and
and  are recovered simply by centering and rescaling the 3D points in
are recovered simply by centering and rescaling the 3D points in  so that they fit inside an enclosing ball of unit radius. The latter is iteratively found by deflating an initial ball until it cannot shrink anymore without losing points in
so that they fit inside an enclosing ball of unit radius. The latter is iteratively found by deflating an initial ball until it cannot shrink anymore without losing points in  (see [16] for more details).
(see [16] for more details).
Rotation
 is taken as one of the three possible candidate matrices including (i) identity4 (i.e., no transformation, denoted none), or one of the transformation matrices resulting from PCA either on (ii) gravity centers or (iii) face normals, of
is taken as one of the three possible candidate matrices including (i) identity4 (i.e., no transformation, denoted none), or one of the transformation matrices resulting from PCA either on (ii) gravity centers or (iii) face normals, of  . The two cases (ii), (iii) will be referred to as PCA and normal PCA (NPCA), respectively, [39, 40].
. The two cases (ii), (iii) will be referred to as PCA and normal PCA (NPCA), respectively, [39, 40].
Axis Reordering and Reflection
This step processes only 3D probe objects and consists in re-ordering and reflecting the three projection planes  , in order to generate
, in order to generate  possible triples of 2D canonical views (i.e.,
possible triples of 2D canonical views (i.e.,  for reordering
for reordering  for reflection). Reflection makes it possible to consider mirrored views of objects while reordering allows us to permute the principal orthogonal axes of an object and therefore permuting the underlying 2D canonical views.
for reflection). Reflection makes it possible to consider mirrored views of objects while reordering allows us to permute the principal orthogonal axes of an object and therefore permuting the underlying 2D canonical views.
For each combination taken from "scaling  translation
translation  3 possible rotations" (see explanation earlier), the objective function (1) is evaluated. The combination
3 possible rotations" (see explanation earlier), the objective function (1) is evaluated. The combination  that minimizes this function is kept as the best transformation. Finally, three canonical views are generated for each object
that minimizes this function is kept as the best transformation. Finally, three canonical views are generated for each object  in the gallery set.
in the gallery set.
3. Multiview Object Description
Again, we extract the three 2D canonical views corresponding to the projection of an object  , according to the framework described earlier. Each 2D view of
, according to the framework described earlier. Each 2D view of  is processed in order to extract and describe external contours using [2]. Our description is based on a multiscale analysis which extracts convexity/concavity coefficients on each contour. Since the latter are strongly correlated through many views of a given object
is processed in order to extract and describe external contours using [2]. Our description is based on a multiscale analysis which extracts convexity/concavity coefficients on each contour. Since the latter are strongly correlated through many views of a given object  , we describe our contours using three up to nine views per reordering and reflection. This reduces redundancy and also speeds up the whole feature extraction and matching process (see Figure 5).
, we describe our contours using three up to nine views per reordering and reflection. This reduces redundancy and also speeds up the whole feature extraction and matching process (see Figure 5).

This figure shows viewpoints when capturing images/silhouettes of 3D models. The left-hand side picture shows the three viewpoints corresponding to the three PCA axes while the right-hand side one, contains also six bisectors. The latter provides better viewpoint distribution over the unit sphere.
In practice, each contour, denoted  , is sampled with
, is sampled with  (2D) points (
(2D) points ( ) and processed in order to extract the underlying convexity/concavity coefficients at
) and processed in order to extract the underlying convexity/concavity coefficients at  different scales [2]. Contours are iteratively filtered (
different scales [2]. Contours are iteratively filtered ( times) using a Gaussian kernel with an increasing scale parameter
times) using a Gaussian kernel with an increasing scale parameter  . Each curve
. Each curve  will then evolve into
will then evolve into  different smooth silhouettes. Let us consider a parameterization of
different smooth silhouettes. Let us consider a parameterization of  using the curvilinear abscissa
using the curvilinear abscissa  as
as  ,
,  , let us also denote
, let us also denote  as a smooth version of
as a smooth version of  resulting from the application of the Gaussian kernel with a scale
resulting from the application of the Gaussian kernel with a scale  (see Figure 6).
(see Figure 6).

Example of extracting the Multiscale Convexity/Concavity (MCC) shape representation: original shape image (a), filtered versions of the original contour at different scale levels (b), final MCC representation for N = 100 contour points and K = 14 scale levels (c).
We use simple convexity/concavity coefficients as local descriptors for each 2D point  on
on  (
( ). Each coefficient is defined as the amount of shift of
). Each coefficient is defined as the amount of shift of  between two consecutive scales
between two consecutive scales  and
and  . Put differently, a convexity/concavity coefficient denoted
. Put differently, a convexity/concavity coefficient denoted  is taken as
is taken as  , here
, here  denotes the
denotes the  norm.
norm.
Runtime
Even though multiview feature extraction is off-line on the gallery set, it is important to achieve this step in (near) real time for the probe data. Notice that the complexity of this step depends mainly on the number of silhouettes and their sampling. Table 1 shows average runtime for alignment and feature extraction, in order to process one object, and for different numbers of silhouettes. These experiments were achieved on a standard 1 Ghz (G4) Power-PC including 512 MB of Ram and 32 MB of VRam.
4. Coarse-to-Fine Matching
4.1. Coarse Pruning
A simple coarse shape descriptor is extracted both on the gallery and probe sets. This descriptor quantifies the distribution of convexity and concavity coefficients through 2D points belonging to different silhouettes of a given object. This coarse descriptor is a multiscale histogram containing 100 bins as the product of  scales of the Gaussian kernel (see Section 3) and
scales of the Gaussian kernel (see Section 3) and  quantification values for convexity/concavity coefficients. Each bin of this histogram counts, through all the viewpoint silhouettes of an object, the frequency of the underlying convexity/concavity coefficients. This descriptor is poor in terms of its discrimination power, but efficient in order to reject almost all the false matches while keeping candidate ones when ranking the gallery objects w.r.t. the probe ones (see also processing time in Figure 9).
quantification values for convexity/concavity coefficients. Each bin of this histogram counts, through all the viewpoint silhouettes of an object, the frequency of the underlying convexity/concavity coefficients. This descriptor is poor in terms of its discrimination power, but efficient in order to reject almost all the false matches while keeping candidate ones when ranking the gallery objects w.r.t. the probe ones (see also processing time in Figure 9).
4.2. Fine Matching by Dynamic Programming
Given are two objects  ,
,  , respectively, from the probe and the gallery sets and the underlying silhouettes/curves
, respectively, from the probe and the gallery sets and the underlying silhouettes/curves  ,
,  . A global scoring function is defined between
. A global scoring function is defined between  ,
,  as the expectation of the matching pseudodistance involving all the silhouettes
as the expectation of the matching pseudodistance involving all the silhouettes  ,
,  as
as

here  is the number of silhouettes per probe image (in practice,
is the number of silhouettes per probe image (in practice,  or
or  , see Section 5).
, see Section 5).
Silhouette matching is performed using dynamic programming. Given two curves  ,
,  , a matching pseudodistance, denoted DSW, is obtained as a sequence of operations (substitution, insertion, and deletion) which transforms
, a matching pseudodistance, denoted DSW, is obtained as a sequence of operations (substitution, insertion, and deletion) which transforms  into
into  [43]. Considering the
[43]. Considering the  samples from
samples from  ,
,  and the underlying local convexity/concavity coefficients
and the underlying local convexity/concavity coefficients  , the DSW pseudodistance is
, the DSW pseudodistance is

here  denotes the
denotes the  -norm,
-norm,  and
and  is the dynamic programming matching function, which assigns for each curvilinear abscissa
is the dynamic programming matching function, which assigns for each curvilinear abscissa  in
in  its corresponding abscissa
its corresponding abscissa  in
in  . Given the distance matrix
. Given the distance matrix  with
with  , the matching function
, the matching function  is found by selecting a path in
is found by selecting a path in  . This path minimizes the number of operations (substitution, deletion, and insertion in order to transform
. This path minimizes the number of operations (substitution, deletion, and insertion in order to transform  into
into  ) and preserves the ordering assumption (i.e., if
) and preserves the ordering assumption (i.e., if  is matched with
is matched with  then
then  should be matched only with
should be matched only with  ,
,  ). We introduce a variant of the standard dynamic programming; instead of examining all the possible matches, we consider only those which belong to a diagonal band of
). We introduce a variant of the standard dynamic programming; instead of examining all the possible matches, we consider only those which belong to a diagonal band of  , that is,
, that is,  is allowed to take only small values (see Figures 7 and 8).
is allowed to take only small values (see Figures 7 and 8).

This figure shows dynamic programming used in order to find the global alignment of two contours.

This figure shows an example of a matching result, between two contours, using dynamic programming.

Evolution of runtime with respect to the pruning parameter k , with 9 views.

This figure shows the percentage of good alignments with respect to the tolerance (angle ε in radian) on a subset of the Watertight dataset.
Dynamic programming pseudodistance provides a good discrimination power and may capture the intraclass variations better than the global distance (discussed in Section 4.1). Nevertheless, it is still computationally expensive but when combined with coarse pruning the whole process is significantly faster and also precise (see Figure 9 and Table 2). Finally, this elastic similarity measure allows us to achieve retrieval while being robust to intraclass object articulations/deformations (observed in the Shrec Watertight set) and also to other effects (including noise) induced by hand-drawn sketches (see Figures 14, 15, 16, and 17).
Runtime
Using the coarse-to-fine querying scheme described earlier, we adjust the speedup/precision trade-off via a parameter  . Given a query, this parameter corresponds to the fraction of nearest neighbors (according to our global descriptor) used in order to achieve dynamic programming. Lower values of
. Given a query, this parameter corresponds to the fraction of nearest neighbors (according to our global descriptor) used in order to achieve dynamic programming. Lower values of  make the retrieval process very fast at the detriment of a slight decrease of precision and vice versa. Figure 9 shows runtime performance with respect to
make the retrieval process very fast at the detriment of a slight decrease of precision and vice versa. Figure 9 shows runtime performance with respect to  on the same hardware platform (with 9 views).
on the same hardware platform (with 9 views).
5. Experiments
5.1. Databases
In order to evaluate the robustness of the proposed framework, we used two datasets. The first one is the Watertight dataset of the Shrec benchmark while the second one is the Princeton Shape Benchmark, widely used in the 3D content-based retrieval community.
Shrec Watertight Dataset
This dataset contains 400 "3D" objects represented by seamless surfaces (without defective holes or gaps). The models of this database have been divided into  classes each one contains
classes each one contains  objects. The 3D models were taken from two sources: the first one is a deformation of an initial subset of objects (octopus, glasses,
objects. The 3D models were taken from two sources: the first one is a deformation of an initial subset of objects (octopus, glasses, ), while the second one is a collection of original 3D models (chair, vase, four legs,
), while the second one is a collection of original 3D models (chair, vase, four legs, ).
).
Princeton Shape Benchmark
This dataset contains 907 "3D" objects organized in 92 classes. This dataset offers a large variety of objects for evaluation.
For the two datasets, each 3D object belongs to a unique class among different semantic concepts with strong variations including human, airplane, chair, and so forth. For instance, the human class contains persons with different poses and appearances "running, seating, walking, etc.", globally the two databases are very challenging.
5.2. Evaluation Criteria
We evaluated our method using recall-precision. Precision is defined as the fraction of relevant retrieved objects over the number of displayed 3D models while recall is defined as the fraction of relevant retrieved objects over the total number of relevant 3D models in the dataset. A plot that approaches the 1-1 corner indicates better retrieval results. In addition to recall/precision plot, we use several quantitative statistics to evaluate the results.
-
(i)
The nearest neighbor (NN). It represents the fraction of the first nearest neighbors which belong to the same class as the query.
-
(ii)
The first-tier (FT) and the second-tier (ST). These measures give the percentage of objects in the same class as the query that appear in the
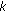 best matches. For a given class
best matches. For a given class  containing
containing 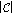 objects,
objects, 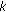 is set to
is set to 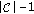 for the first-tier measure while
for the first-tier measure while  is set to
is set to 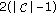 for second-tier (ST).
for second-tier (ST). -
(iii)
Finally, we use the discounted cumulative gain (DCG) measure which gives more importance to well-ranked models. Given a query and a list of ranked objects, we define for each ranked object a variable
 equal to
equal to 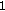 if its class is equal to the class of the query and
if its class is equal to the class of the query and  otherwise. The DCG measure is then defined as.
otherwise. The DCG measure is then defined as. 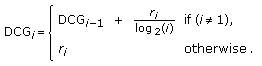 (4)
(4)
 best matches. For a given class
best matches. For a given class  containing
containing 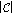 objects,
objects, 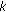 is set to
is set to 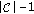 for the first-tier measure while
for the first-tier measure while  is set to
is set to 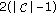 for second-tier (ST).
for second-tier (ST). equal to
equal to 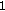 if its class is equal to the class of the query and
if its class is equal to the class of the query and  otherwise. The DCG measure is then defined as.
otherwise. The DCG measure is then defined as. 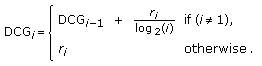
We take the expectation of these measures on the entire database, that is, by taking all the possible object queries.
5.3. Performance and Discussion
Alignment
Figure 10 shows the performance of our alignment method presented in Section 2 on the Watertight dataset. For that purpose, we define a ground truth, by manually aligning  "3D" models5 (
"3D" models5 ( categories each one has
categories each one has  objects) in order to make their canonical views parallel to the canonical planes
objects) in order to make their canonical views parallel to the canonical planes  ,
,  and
and  (see Figure 11,
(see Figure 11,  and also Figure 4). The error is then defined as the deviation (angle in degrees or radians) of the automatically aligned objects w.r.t. the underlying ground truth (see Figure 11,
and also Figure 4). The error is then defined as the deviation (angle in degrees or radians) of the automatically aligned objects w.r.t. the underlying ground truth (see Figure 11,  ).
).
Different alignment methods were compared including the classic (PCA), normal PCA (NPCA), and our method. We also show the alignment error of the initial (not) aligned database (None). The plot in Figure 10 shows a comparison of the percentage of 3D objects in the database, which are automatically and correctly aligned up to an angle  w.r.t. the underlying 3D models in the ground truth.
w.r.t. the underlying 3D models in the ground truth.
Table 2 illustrates the statistics defined earlier. We clearly see that our new alignment method gives better results compared to the classical PCA and NPCA. Again our pose estimation method makes it possible to extract several canonical 2D views and for each one we compared results using either three or nine 2D views per object (see results in Figure 13 and rows 4 and 5 of Table 2). Regarding the influence of the number of views, the performances increase for the two datasets.

This figure shows examples of 3D object alignment with different error angles (denoted ε, see also Figure 10).

This figure shows the evolution of the NN, FT, ST, and DCG measures (in %) w. r.t. the pruning size k, on the two datasets (Watertight (a)) and Princeton (b). We found that makes it possible to reject almost all the false matches in the gallery set. We found also that the CPU runtime scales linearly with respect to k.

This figure shows comparison of precision versus recall (with our pose estimation method + pruning threshold k = 50), using 3 silhouettes (in blue) and 9 silhouettes (in red) per object, on the Watertight dataset.

Precision/recall plot for different photo sets ( fish and teddy classes) queried on the Watertight dataset (Setting includes 3 views, our alignment and pruning with ).

Precision/recall plot for different hand-drawn sketches ( chair and human classes) queried on the Watertight dataset (Setting includes 3 views, our alignment and pruning with ).

Precision/recall plot for different photo sets ( commercial and hand classes) queried on the Princeton dataset (Setting includes 3 views, our alignment and Pruning with ).

Precision/recall plot for different hand-drawn sketches ( glass with stem and eyeglasses classes) queried on the Princeton dataset (Setting includes 3 views, our alignment and pruning with ).
Coarse-to-Fine Retrieval
In order to control/reduce the runtime to process and match local signatures, we used our pruning approach based on the global signature discussed in Section 4.1. The parameter  allows us to control the trade-off between robustness and speed of the retrieval process. A small value of
allows us to control the trade-off between robustness and speed of the retrieval process. A small value of  gives real-time (online) responses with an acceptable precision while a high value requires more processing time but gives better retrieval performance. Figure 12 shows the NN, FT, ST, and DCG measures for different pruning thresholds
gives real-time (online) responses with an acceptable precision while a high value requires more processing time but gives better retrieval performance. Figure 12 shows the NN, FT, ST, and DCG measures for different pruning thresholds  . Table 2 shows different statistics for
. Table 2 shows different statistics for  ,
,  and
and  .
.
Table 3 shows also the performance of matching using dynamic programming versus adhoc naive matching (i.e., through the curvilinear abscissa,  in (2). Dynamic programming outperforms the naive matching by allowing
in (2). Dynamic programming outperforms the naive matching by allowing  to be equal to
to be equal to  (
( ) in contrast to naive matching (
) in contrast to naive matching ( ); this clearly makes dynamic programming more flexible in order to handlelocal deformations (see again Table 3).
); this clearly makes dynamic programming more flexible in order to handlelocal deformations (see again Table 3).
5.4. Benchmarking and Comparison
Shrec Watertight Dataset
First, comparisons of our approach with respect to different methods/participants are available and were generated by a third party in the Shrec'09 Structural Shape Retrieval contest (see Table 4). This dataset contains 200 objects and results were evaluated on 10 queries. The performance of this shape retrieval contest were measured using 1st (10 objects) and 2nd (20 objects) tier precision and recall, presented as the F-measure. This is a global measure which provides us with the overall retrieval performance.
We submitted in this benchmark four runs.
-
(i)
Run 1 (MCC 1): 9 silhouettes and pruning threshold
 . The average runtime for each query is 0.03 s.
. The average runtime for each query is 0.03 s. -
(ii)
Run 2 (MCC 2): 9 silhouettes and pruning threshold
 . The average runtime for each query is 9.4 s.
. The average runtime for each query is 9.4 s. -
(iii)
Run 3 (MCC 3): 9 silhouettes and pruning threshold
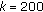 . The average runtime for each query is 36.2 s.
. The average runtime for each query is 36.2 s. -
(iv)
Run 4 (MCC 4): 3 silhouettes and pruning threshold
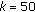 . The average runtime for each query is 3.1 s.
. The average runtime for each query is 3.1 s.
 . The average runtime for each query is 0.03 s.
. The average runtime for each query is 0.03 s. . The average runtime for each query is 9.4 s.
. The average runtime for each query is 9.4 s.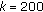 . The average runtime for each query is 36.2 s.
. The average runtime for each query is 36.2 s.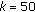 . The average runtime for each query is 3.1 s.
. The average runtime for each query is 3.1 s.We can see in Table 4 that the third run of our method (shown in bold) outperforms the others for the first-tier and is equivalent to the C SID CMVD 3 for the second-tier (see Table 7 for the significance of method acronyms). The results for the second run are similar to the BF SIFT 1 and to the C SID CMVD 1 methods.
Princeton Shape Benchmark Dataset
Table 5 shows a comparison of the four runs of our approach on the Princeton Shape Benchmark; these runs outperform the other participating methods (described in [4, 10, 34]).
Hand-Drawn Sketches and Photos
Finally, we compared our approach with respect to two querying schemes including (i) 2 hand-drawn sketches per mental category6 or (ii) silhouettes from multiview real pictures. In both scenarios, gallery data are processed in the same way as inTable 4 (MCC 4),that is, by aligning 3D objects using our pose estimation method and processing them in order to extract 3 views. The results on the two databases, in Figures 14 to 17, Table 6 and Figure 18, show very encouraging performances on real data (sketches and real pictures) and clearly open very promising directions for further extensions and improvements.

Retrieval results with different scenarios, sketch, photos, and 3D models. In case of photos, queries may correspond to one or multiple views of the same or different objects.
6. Conclusion
We introduced in this paper a novel and complete framework for "2D-to-3D" object retrieval. The method makes it possible to extract canonical views using a generative approach combined with principal component analysis. The underlying silhouettes/contours are matched using dynamic programming in a coarse-to-fine way that makes the search process efficient and also effective as shown through extensive evaluations.
One of the major drawbacks of dynamic programming resides in the fact that it is not a metric, so one cannot benefit from lossless acceleration techniques which provide precise results and efficient computation. Our extension is to tackle this issue by introducing new matching approaches that allow us to speedup the search process while keeping high precision.
Endnotes
1. Even though in a chaotic way because of the absence of consistent alignments of 3D models.
2. Obviously, normalization is achieved on the probe set only when queries are 3D models. As for the 2D photo or the sketch scenarios, one assumes that at least three silhouettes are available corresponding to three canonical views.
3. Again, this is in accordance with cognitive psychology of human perception (defined, e.g., in [25]).
4. The initial object pose is assumed to be the canonical one.
5. http://perso.enst.fr/~sahbi/file/Watertight_AlignmentGroundTruth.zip.
6. The user will imagine a category existing in the Watertight gallery set and will draw it.
References
Hartveldt J, Spagnuolo M, Axenopoulos A, et al.: SHREC'09 track: structural shape retrieval on watertight models. Proceedings of Eurographics Workshop on 3D Object Retrieval, March 2009, Munich, Germany 77-83.
Adamek T, O'Connor NE: A multiscale representation method for nonrigid shapes with a single closed contour. IEEE Transactions on Circuits and Systems for Video Technology 2004,14(5):742-753. 10.1109/TCSVT.2004.826776
Ankerst M, Kastenmüller G, Kriegel HP, Seidl T: Nearest neighbor classification in 3D protein databases. Proceedings of the 7th International Conference on Intelligent Systems for Molecular Biology (ISMB '99), August 1999, Heidelberg, Germany 34-43.
Ansary TF: Model retrieval using 2d characteristic views, Ph.D. thesis. 2006.
Bellman R: Dynamic programming. Science 1966,153(3731):34-37. 10.1126/science.153.3731.34
Biasotti S, Giorgi D, Marini S, Spagnuolo M, Falcidieno B: A comparison framework for 3D object classification methods. Proceedings of the International Workshop on Multimedia Content Representation, Classification and Security (MRCS '06), 2006, Lecture Notes in Computer Science 4105: 314-321.
Biasotti S, Marini S, Spagnuolo M, Falcidieno B: Sub-part correspondence by structural descriptors of 3D shapes. Computer Aided Design 2006,38(9):1002-1019. 10.1016/j.cad.2006.07.003
Del Bimbo A, Pala P: Content-based retrieval of 3D models. ACM Transactions on Multimedia Computing, Communications and Applications 2006,2(1):20-43. 10.1145/1126004.1126006
Bustos B, Keim D, Saupe D, Schreck T, Vranić D: An experimental comparison of feature-based 3D retrieval methods. In Proceedings of the 2nd International Symposium on 3D Data Processing, Visualization, and Transmission, September 2004, Thessaloniki, Greece. IEEE Computer Society; 215-222.
Chaouch M, Verroust-Blondet A: Enhanced 2D/3D approaches based on relevance index for 3D-shape retrieval. Proceedings of IEEE International Conference on Shape Modeling and Applications (SMI '06), June 2006, Matsushima, Japan 36.
Chaouch M, Verroust-Blondet A: A new descriptor for 2D depth image indexing and 3D model retrieval. Proceedings 14th IEEE International Conference on Image Processing (ICIP '07), September 2006 6: 373-376.
Chen D: Three-dimensional model shape description and retrieval based on lightfield descriptors, Ph.D. thesis. Department of Computer Science and Information Engineer, National Taiwan University, Taipei, Taiwan; June 2003.
Chen D, Ouhyoung M: A 3d model alignment and retrieval system. Proceedings of the International Workshop on Multimedia Technologies, December 2002 1436-1443.
Chen D-Y, Tian X-P, Shen Y-T, Ouhyoung M: On visual similarity based 3D model retrieval. Computer Graphics Forum 2003,22(3):223-232. 10.1111/1467-8659.00669
Ansary TF, Daoudi M, Vandeborre J-P: A Bayesian 3-D search engine using adaptive views clustering. IEEE Transactions on Multimedia 2007,9(1):78-88.
Fischer K, Gärtner B: The smallest enclosing ball of balls: combinatorial structure and algorithms. International Journal of Computational Geometry and Applications 2004,14(4-5):341-378.
Funkhouser T, Min P, Kazhdan M, et al.: A search engine for 3D models. ACM Transactions on Graphics 2003,22(1):83-105. 10.1145/588272.588279
Funkhouser T, Shilane P: Partial matching of 3d shapes with priority-driven search. Proceedings of the 4th Eurographics Symposium on Geometry Processing, June 2006, Cagliari, Italy 131-142.
Hilaga M, Shinagawa Y, Kohmura T, Kunii TL: Topology matching for fully automatic similarity estimation of 3D shapes. Proceedings of the 28th Annual Conference on Computer Graphics and Interactive Techniques (SIGGRAPH '01), August 2001, Los Angeles, Calif, USA 203-212.
Horn BKP: Extended Gaussian images. Proceedings of the IEEE 1984,72(12):1671-1686.
Jin H, Soatto S, Yezzi AJ: Multi-view stereo reconstruction of dense shape and complex appearance. International Journal of Computer Vision 2005,63(3):175-189. 10.1007/s11263-005-6876-7
Kang SB, lkeuchi K: Determining 3-d object pose using the complex extended Gaussian image. Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, June 1991, Maui, Hawaii, USA 580-585.
Kazhdan MM, Funkhouser TA, Rusinkiewicz S: Rotation invariant spherical harmonic representation of 3d shape descriptors. In Proceedings of the Eurographics/ACM SIGGRAPH Symposium on Geometry Processing (SGP '03), June 2003, Aachen, Germany. Eurographics Association; 156-165.
Laga H, Takahashi H, Nakajima M: Spherical wavelet descriptors for content-based 3D model retrieval. Proceedings of IEEE International Conference on Shape Modeling and Applications (SMI '06), June 2006, Matsushima, Japan 15.
Leek EC: Effects of stimulus orientation on the identification of common polyoriented objects. Psychonomic Bulletin and Review 1998,5(4):650-658. 10.3758/BF03208841
Mahmoudi S, Daoudi M: 3D models retrieval by using characteristic views. Proceedings of the 16th International Conference on Pattern Recognition (ICPR '02), August 2002, Quebec, Canada (2):457-460.
NIST : Shape retrieval contest on a new generic shape benchmark. 2004, http://www.itl.nist.gov/iad/vug/sharp/benchmark/shrecGeneric/Evaluation.html
Novotni M, Klein R: 3D Zernike descriptors for content based shape retrieval. In Proceedings of the 8th Symposium on Solid Modeling and Applications, 2003, Seattle, Wash, USA. ACM Press; 216-225.
Ohbuchi R, Kobayashi J: Unsupervised learning from a corpus for shape-based 3D model retrieval. Proceedings of the ACM International Multimedia Conference and Exhibition, October 2006, Santa Barbara, Calif, USA 163-172.
Ohbuchi R, Nakazawa M, Takei T: Retrieving 3d shapes based on their appearance. In Proceedings of the 5th ACM SIGMM International Workshop on Multimedia Information Retrieval (MIR '03), 2003 Edited by: Sebe N, Lew MS, Djeraba C. 39-45.
Osada R, Funkhouser T, Chazelle B, Dobkin D: Matching 3d models with shape distributions. In Proceedings of the International Conference on Shape Modeling and Applications (SMI '01), May 2001, Los Alamitos, Calif, USA. Edited by: Werner B. IEEE Computer Society; 154-166.
Papadakis P, Pratikakis I, Perantonis S, Theoharis T, Passalis G: SHREC'08 entry: 2D/3D hybrid. Proceedings of IEEE International Conference on Shape Modeling and Applications (SMI '08), June 2008 247-248.
Saupe D, Vranic DV: 3d model retrieval with spherical harmonics and moments. In Proceedings of the 23rd DAGM-Symposium on Pattern Recognition, 2001, Lecture Notes in Computer Science. Volume 2191. Edited by: Radig B, Florczyk S. Springer; 392-397.
Shilane P, Min P, Kazhdan M, Funkhouser T: The Princeton shape benchmark. Proceedings of the Shape Modeling International (SMI '04), 2004, Washington, DC, USA 167-178.
Tangelder JWH, Veltkamp RC: A survey of content based 3D shape retrieval methods. Proceedings of the Shape Modeling International (SMI '04), June 2004 145-156.
Tierny J, Vandeborre J-P, Daoudi M: 3d mesh skeleton extraction using topological and geometrical analyses. Proceedings of the 14th Pacific Conference on Computer Graphics and Applications, October 2006, Taipei, Taiwan 85-94.
Tung T, Schmitt F: The augmented multiresolution Reeb graph approach for content-based retrieval of 3D shapes. International Journal of Shape Modeling 2005,11(1):91-120. 10.1142/S0218654305000748
Vranić DV: An improvement of rotation invariant 3D-shape descriptor based on functions on concentric spheres. Proceedings of IEEE International Conference on Image Processing, 2003 3: 757-760.
Vranic DV: 3D model retrieval, Ph.D. thesis. University of Leipzig; 2004.
Vranić DV, Saupe D, Richter J: Tools for 3D-object retrieval: Karhunen-Loeve transform and spherical harmonics. In Proceedings of the 4th IEEE Workshop on Multimedia Signal Processing, September 2001, Budapest, Hungary Edited by: Dugelay J-L, Rose K. 293-298.
Zaharia T, Prêteux F: 3D versus 2D/3D shape descriptors: a comparative study. Imaging Processing: Algorithms and Systems III, January 2004, San Jose, Calif, USA, Proceedings of SPIE 5298: 47-58.
Zarpalas D, Daras P, Axenopoulos A, Tzovaras D, Strintzis MG: 3D model search and retrieval using the spherical trace transform. EURASIP Journal on Advances in Signal Processing 2007, 2007:-14.
Tierny J, Vandeborre J-P, Daoudi M: Invariant high level reeb graphs of 3D polygonal meshes. Proceedings of the 2rd International Symposium on 3D Data Processing, Visualization, and Transmission (3DPVT '06), June 2007, Chapel Hill, NC, USA 105-112.
Acknowledgment
This work was supported by the European Network of Excellence KSpace and the French National Research Agency (ANR) under the AVEIR Project, ANR-06-MDCA-002.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
Open Access This article is distributed under the terms of the Creative Commons Attribution 2.0 International License (https://creativecommons.org/licenses/by/2.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
About this article
Cite this article
Napoléon, T., Sahbi, H. From 2D Silhouettes to 3D Object Retrieval: Contributions and Benchmarking. J Image Video Proc 2010, 367181 (2010). https://doi.org/10.1155/2010/367181
Received:
Revised:
Accepted:
Published:
DOI: https://doi.org/10.1155/2010/367181