- Research Article
- Open access
- Published:
Motion Pattern Extraction and Event Detection for Automatic Visual Surveillance
EURASIP Journal on Image and Video Processing volume 2011, Article number: 163682 (2011)
Abstract
Efficient analysis of human behavior in video surveillance scenes is a very challenging problem. Most traditional approaches fail when applied in real conditions and contexts like amounts of persons, appearance ambiguity, and occlusion. In this work, we propose to deal with this problem by modeling the global motion information obtained from optical flow vectors. The obtained direction and magnitude models learn the dominant motion orientations and magnitudes at each spatial location of the scene and are used to detect the major motion patterns. The applied region-based segmentation algorithm groups local blocks that share the same motion direction and speed and allows a subregion of the scene to appear in different patterns. The second part of the approach consists in the detection of events related to groups of people which are merge, split, walk, run, local dispersion, and evacuation by analyzing the instantaneous optical flow vectors and comparing the learned models. The approach is validated and experimented on standard datasets of the computer vision community. The qualitative and quantitative results are discussed.
1. Introduction
In the recent years, there has been an increasing demand for automated visual surveillance systems: more and more surveillance cameras are used in public areas such as airports, malls, and subway stations. However, optimal use is not made of them since the output is observed by a human operator, which is expensive and unreliable. Automated surveillance systems try to integrate real-time and efficient computer vision algorithms in order to assist human operators. This is an ambitious goal which has attracted an increasing amount of researchers over the years. They are used as an active real-time medium which allows security teams to take prompt actions in abnormal situations or simply label the video streams to improve the indexing/retrieval platforms. These kinds of intelligent systems are applicable to many situations, such as event detection, traffic and people-flow estimation, and motion pattern extraction. In this paper we will focus on motion pattern extraction and event detection applications.
Learning typical motion patterns from video scenes is important in automatic visual surveillance. It can be used as a mid-level feature in order to perform a higher-level analysis of the scene under surveillance. It consists of extracting usual or repetitive patterns of motion, and this information is used in many applications such as marketing and surveillance. The extracted patterns are used to estimate consumer demographics in public spaces or to analyze traffic trends in road traffic scenes.
Motion patterns are also used to detect the events that occur in the scene under surveillance by improving the detection, the tracking and behavior modeling, and understanding of the object in the scene. We define an event as the interesting phenomena which captures the user's attention (e.g., running event in crowd, goal event in sports challenges, traffic accidents, etc.) [1]. An event occurs in a high-dimensional spatiotemporal space and is described by its spatial location, its time interval, and its label. We will focus our approach on six crowd-related events which are labeled: walking, running, splitting, merging, local dispersion, and evacuation.
This paper describes a real-time approach for modeling the scenes under surveillance. The approach consists of modeling the motion orientations over a certain number of frames in order to estimate a direction model. This is done by performing a circular clustering at each spatial location of the scene in order to determine their major orientations. The direction model has various uses depending on the number of frames used for its estimation. In this work, we put forward two applications. The first one consists of detecting typical motion patterns of a given video sequence. This is performed by estimating the direction model by using all the frames of that sequence; the direction model will contain the major motion orientations of the sequence at each spatial location. Then we apply a region-based segmentation algorithm to the direction model. The retrieved clusters are the typical motion patterns, as shown in Figure 1 where three motion patterns are detected. This figure shows the entrance lobby of the INRIA labs. Each motion pattern in the black frame is defined by its main orientation and its area on the scene.

Learned motion patterns on a sequence from the Caviar dataset.
The second application is motion segmentation, which detects groups of objects that have the same motion orientation. We locate groups of persons on a frame by determining the direction model of the immediate past and future of that frame, and then grouping similar locations on the direction model. Then, we use the positions, distances, orientations, and velocities of the groups to detect the events described earlier.
Our work is based on the idea that entities that have the same orientation form a single unit. This is inspired by gestaltism or Gestalt psychology [2], a theory of mind and brain positing which states in the law of common fate that elements with the same moving direction are perceived as a collective or unit. In this work, we rely mostly on motion orientation as opposed to a semidirectional model [3] because gestaltism does not consider motion speed. In fact, we can see in real life that moving objects that follow the same patterns do not necessarily move at the same speed. For example, in a one-way road, cars move at different speeds while sharing the same motion pattern. In addition, augmenting the direction model with the motion speed information will increase the computation burden which is not desired in real-time systems.
The remainder of this paper is organized as follows: firstly, in Section 2 we highlight some relevant works on motion pattern recognition and event detection in automatic video surveillance. Section 3 details the estimation of the Direction Model. Then Section 4 presents the motion pattern extraction algorithm using the direction model. In Section 5 we detail the event recognition module. We present the experiments and result of our motion pattern extraction and event detection approaches in Section 6. The experiments were performed using datasets retrieved from the web (such as PETS (http://www.cvg.rdg.ac.uk/PETS2009/index.html) and CAVIAR (http://groups.inf.ed.ac.uk/vision/CAVIAR/CAVIARDATA1/) datasets) and annotated by a human expert. Finally, we give our concluding remarks and discuss potential extensions of the work in Section 7.
2. Related Works
The problems of motion pattern extraction and crowd event detection in visual surveillance are not new [4–8]. These problems are related because in general the approaches detect events using motion patterns following these steps: (i) detection and tracking of the moving objects present in the scene, (ii) extraction of motion patterns from the tracks, and eventually (iii) detection of events using motion patterns information.
2.1. Object Detection and Tracking
Many object detection and tracking approaches have been proposed in the literature. A well-known method consists in tracking blobs extracted via background subtraction approaches [9–11] where a blob represents a physical object in the scene such as a car or a person. The blobs are tracked using filters such as the Kalman filter or the particle filter. These approaches have the advantage of directly mapping a blob to a physical object which facilitates object identification. However, they experience poor performance when the lighting conditions change and when the number of objects is very important and occluded.
Another type of approach detects and tracks the points of interest (POI) [12–14]. These points consist in corners, edges, or other features which are relevant for tracking. They are then tracked using optical flow techniques. The detection and tracking of POIs requires less computation resources. However, physical objects are not directly detected because the objects here are the POIs. Thus, physical object identification is more complex using these approaches.
2.2. Motion Pattern Extraction
Once the objects have been detected and extracted, the motion patterns can be extracted using various algorithms that we classify as follows.
Iterative Optimization
These approaches group the trajectories of moving objects using simple classifiers such as K-means. Hu et al. [15] generate trajectories using fuzzy K-means algorithms for detecting foreground pixels. Trajectories are then clustered hierarchically and each motion pattern is represented with a chain of Gaussian distributions. These approaches have the advantage of being simple yet efficient. However, the number of clusters must be specified manually and the data must be of equal length, which weakens the dynamic aspect.
Online Adaptation
These approaches integrate new tracks on the fly as opposed to iterative optimization approaches. This is possible using an additional parameter which controls the rate of updates. Wang et al. [16] propose a trajectory similarity measure to cluster the trajectories and then learn the scene model from trajectory clusters. Basharat et al. [17] learn patterns of motion as well as patterns of object motion and size. This is performed by modeling pixel-level probability density functions of an object's position, speed, and size. The learned models are then used to detect abnormal tracks or objects. These approaches are adapted to real-time applications and time-varying scenes because the number of clusters is not specified and they are updated over time. There is also no need for the maintenance of a training database. However, it is difficult to select a criterion for new cluster initialization that prevents the inclusion of outliers and insures optimality.
Hierarchical Methods
These approaches consider a video sequence as the root node of a tree where the bottom nodes correspond to individual tracks. Hu et al. [18] detect sequence's motion patterns by clustering its motion flow field, in which each motion pattern consists of a group of flow vectors participating in the same process or motion. However, the suggested algorithm is designed only for structured scenes and fails on unstructured ones. It requires that a maximum number of patterns are specified and for that number to be slightly higher than the number of desired clusters. Zhang et al. [19] model pedestrians' and vehicles' trajectories as graph nodes and apply a graph-cut algorithm to group the motion patterns together. These approaches are well suited for graph theory techniques which make binary divisions (such as max-flow and min-cut). In addition, the multiresolution clustering allows a clever choice of the number of clusters. The drawback is the quality of the clusters which is dependent on the decision of how to split (merge) a set that is not generally reflected along the tree.
Spatiotemporal Approaches
These approaches use time as a third dimension and consider the video as a 3d volume ( ,
,  ,
,  ). Yu and Medioni [20] learn the patterns of moving vehicles from airborne video sequences. This is achieved using a 4D representation of motion vectors, before applying tensor voting and motion segmentation. Lin et al. [21] transform the video sequence into a vector space using a Lie algebraic representation. Motion patterns are then learned using a statistical model applied to the vector space. Gryn et al. [22] introduce the direction map as a representation that captures the spatiotemporal distribution of motion direction across regions of interest in space and time. It is used for recovering direction maps from video, constructing direction map templates to define target patterns of interest, and comparing predefined templates to newly acquired video for pattern detection and localization. However, the direction map is able to capture only a single major orientation or motion modality at each spatial location of the scene.
). Yu and Medioni [20] learn the patterns of moving vehicles from airborne video sequences. This is achieved using a 4D representation of motion vectors, before applying tensor voting and motion segmentation. Lin et al. [21] transform the video sequence into a vector space using a Lie algebraic representation. Motion patterns are then learned using a statistical model applied to the vector space. Gryn et al. [22] introduce the direction map as a representation that captures the spatiotemporal distribution of motion direction across regions of interest in space and time. It is used for recovering direction maps from video, constructing direction map templates to define target patterns of interest, and comparing predefined templates to newly acquired video for pattern detection and localization. However, the direction map is able to capture only a single major orientation or motion modality at each spatial location of the scene.
Cooccurence Methods
These methods take advantage of the advances in document retrieval and natural language processing. The video is considered as a document and a motion pattern as a bag of words. Rodriguez et al. [23] propose to model various crowd behavior (or motion) modalities at different locations of the scene by using a Correlated Topic Model (CTM). The learned model is then used as a priori knowledge in order to improve the tracking results. This model uses motion vector orientation, subsequently quantized into four motion directions, as a low-level feature. However, this work is based on the manual division of the video into short clips and further investigation is needed as to the duration of those clips. Stauffer and Grimson [24] use a real-time tracking algorithm in order to learn patterns of motion (or activity) from the obtained tracks. They then apply a classifier in order to detect unusual events. Thanks to the use of cooccurrence matrix from a finite vocabulary, these approaches are independent from the trajectory length. However, the vocabulary size is limited for effective clustering and time ordering is sometimes neglected.
Evaluation Approaches
The evaluation of motion pattern extraction approaches is difficult and time consuming for a human operator. Although the best evaluation is still performed by a human expert, we find approaches that define metrics and evaluation methodologies for automatic and in-depth evaluation. Morris and Trivedi [25] perform a comparative evaluation on approaches that uses clustering methodologies in order to learn trajectory patterns. Eibl and Brändle [26] find motion patterns by clustering optical flow fields and propose an evaluation approach using clustering methods for finding dominant optical flow fields.
2.3. Event Detection
The majority of the methodologies proposed for this category focus on detecting unusual (or abnormal) behavior. This kind of result is relatively sufficient for a video surveillance system. However, labeling events is more pertinent and challenging. Ma et al. [27] model each of the spatiotemporal patches of the scene using dynamic textures. They then apply a suitable distance metric between patches in order to segment the video into spatiotemporal regions showing similar patterns and recognizing activities without explicitly detecting individuals in the scene. While many approaches rely on motion vectors (or optical flow vectors), this approach relies on that dynamic textures show more possibilities. However, they require a lot of processing power and use gray level images which contain less information than a color image.
Kratz and Nishino [28] learn the behavior of extremely crowded scenes by modeling the motion variation of local space-time volumes and their spatiotemporal statistical behavior. This statistical framework is then used to detect abnormal behavior. Andrade et al. [29, 30] combine Hidden Markov Models, spectral clustering, and principal component analysis of optical flow vectors for detecting crowd emergency scenarios. However, their experiments were carried out on simulated data. Ali and Shah [31] use Lagrangian particle dynamics for the detection of flow instabilities which is an efficient methodology only for the segmentation of high-density crowd flows (marathons, political events, etc.). Li et al. [32] propose a scene segmentation algorithm based on a static model based on a hierarchical pLSA (probabilistic latent semantic analysis) which divides the scene into semantic regions, where each of them consists of an area that contains a set of correlated atomic events. This approach is able to detect static abnormal behaviors in a global context and does not consider the duration of behaviors. Wang et al. [33] model events by grouping low-level motion features into topics using hierarchical Bayesian models. This method processes simple local motion features and ignores global context. Thus, it is well suited for modeling behavior correlations between stationary and moving objects but cannot model complex behaviors that occur on a big area of the scene.
Ihaddadene and Djeraba [34] detect collapsing situations in a crowd scene based on a measure describing the degree of organization or cluttering of the optical flow vectors in the frame. This approach works on unidirectional areas (e.g., elevators). Mehran et al. [35] use a scene structure-based force model in order to detect abnormal behavior. In this force model, an individual, when moving in a particular scene, is subject to the general and local forces that are functions of the layout of that scene and the motional behavior of other individuals in the scene.
Adam et al. [36] detect unusual events by analyzing specified regions on the video sequence called monitors. Each monitor extracts local low-level observations associated with its region. A monitor uses a cyclic buffer in order to calculate the likelihood of the current observation with respect to previous observations. The results from multiple monitors are then integrated in order to alert the user of an abnormal behavior. Wright and Pless [37] determine persistent motion patterns by a global joint distribution of independent local brightness gradient distributions. This huge, random variable is modeled with a Gaussian mixture model. The last approach assumes that all motions in a frame are coherent (e.g., cars); situations in which pedestrians move independently violate these assumptions.
Our approach contributes to the detection of major orientations in complex scenes by building an online probabilistic model of motion orientation on the scene in real-time conditions. The direction model can be considered an extension of the direction map because it captures more than one motion modality at each of the scene's spatial locations. It also contributes to crowd event detection by tracking groups of people as a whole instead of tracking each person individually, which facilitates the detection of crowd events such as merging or splitting.
3. Direction Model
In this section we describe the construction of the direction model. Its purpose is to indicate the tendency of motion direction for each of the scene's spatial locations. We provide an algorithmic overview of the proposed methodology. Its logical blocks are illustrated in Figure 2.

Direction model creation steps.
Given a sequence of frames, the main steps involved in the estimation direction model are (i) computation of optical flow between each two successive frames resulting in a set of motion vectors, (ii) grouping of motion vectors in the corresponding block, and (iii) circular clustering of the motion vector orientation in each block. The resulting clusters for each block at the end of the video constitute the direction model. Figure 3 illustrates the three steps.

Representation of the steps involved in the estimation of the direction model for a sequence of frames. Input framesOptical flow estimationEstimated direction model for the input frames
The direction model creation is an iterative process composed of two stages. The first stage involves the estimation of optical flow vectors. The second one consists of updating the Direction Model with the newly obtained data.
3.1. Estimation of the Optical Flow Vectors
In this step, we start by extracting a set of points of interest from each input frame. We consider the Harris corner to be a point of interest [38]. We also consider that, in video surveillance scenes, camera positions and lighting conditions allow a large number of corner features to be captured and tracked easily.
Once we have defined the set of points of interest, we track these points over the next frames using optical flow techniques. For this, we resort to a Kanade-Lucas-Tomasi feature tracker [14, 39] which matches features between two cinsecutive frames. The result is a set of four-dimensional vectors  :
:

where  and
and  are the image location coordinates of feature
are the image location coordinates of feature  ,
,  is the motion direction of feature
is the motion direction of feature  , and
, and  is the motion magnitude of feature
is the motion magnitude of feature  . It corresponds to the distance between feature
. It corresponds to the distance between feature  in frame
in frame  and its corresponding feature in frame
and its corresponding feature in frame  .
.
This step also allows the removal of static and noise features. Static features move less than a minimum magnitude. By contrast, noise features have magnitudes that exceed the threshold. In our experiments, we set the minimum motion magnitude to 1 pixel per frame and the maximum to 20 pixels per frame.
3.2. Grouping Motion Vectors by Block
The next step consists of grouping motion vectors by blocks. The camera view is divided into  blocks. Each motion vector is attached to the suitable block following its original coordinates. A block will represent the local motion tendency inside that block. Each block is considered to have a square shape and to be of equal size. Smaller block sizes give better results but require a longer processing time.
blocks. Each motion vector is attached to the suitable block following its original coordinates. A block will represent the local motion tendency inside that block. Each block is considered to have a square shape and to be of equal size. Smaller block sizes give better results but require a longer processing time.
3.3. Circular Clustering in Each Block
The direction model is an improved direction map [34] that supports multiple orientations at each spatial location. In this section, we present the details of the building of the direction model. For this, we assume for each block the following probabilistic model:

where the parameters are  such that
such that  . In other words, we assume that we have
. In other words, we assume that we have  mixed von Mises densities with
mixed von Mises densities with  mixing coefficients. We choose
mixing coefficients. We choose  to represent the four cardinal points.
to represent the four cardinal points.  is the von Mises distribution defined by the following probability density function:
is the von Mises distribution defined by the following probability density function:

where  ,
,  are the parameters of the
are the parameters of the  th distribution.
th distribution.  is its mean orientation,
is its mean orientation,  is its dispersion parameter, and
is its dispersion parameter, and  is the modified Bessel function of the first kind and order 0 defined by
is the modified Bessel function of the first kind and order 0 defined by

With each new frame, the values of  are updated with the new vector set using circular clustering. Instead of using an exact EM algorithm over circular data, we perform an online
are updated with the new vector set using circular clustering. Instead of using an exact EM algorithm over circular data, we perform an online  -means approximation described in [11] which is originally used for building a mixture of Gaussian distribution. The algorithm is adapted to deal with circular data and considers the inverse of the variance as the dispersion parameter;
-means approximation described in [11] which is originally used for building a mixture of Gaussian distribution. The algorithm is adapted to deal with circular data and considers the inverse of the variance as the dispersion parameter;  . Figure 4 shows the cluster thus obtained and the corresponding distribution's probability density.
. Figure 4 shows the cluster thus obtained and the corresponding distribution's probability density.

Representation of estimated clusters and density of the input data. Input dataEstimated clustersProbability density around the unit circle
The direction model is made up of the whole mixture distribution as estimated for each of the scene's blocks.
4. Detecting Motion Patterns
Given an input video, we compute its direction model which estimates for each block up to  major orientations. In other words, dominant motion orientations are learned at each block (or spatial location). Since motion patterns are the regions of the scene that share the same motion orientation behavior, thus, motion pattern detection can be formulated as a problem of clustering the blocks of the direction model (a motion pattern can be considered as a cluster). We refer to gestaltism in order to find grouping factors such as proximity, similarity, closure, simplicity, and common fate. We then detect the scene's dominant motion patterns by applying a peculiar bottom-up region-based segmentation algorithm to the direction model's blocks. Figure 5 shows the output of our algorithm on a
major orientations. In other words, dominant motion orientations are learned at each block (or spatial location). Since motion patterns are the regions of the scene that share the same motion orientation behavior, thus, motion pattern detection can be formulated as a problem of clustering the blocks of the direction model (a motion pattern can be considered as a cluster). We refer to gestaltism in order to find grouping factors such as proximity, similarity, closure, simplicity, and common fate. We then detect the scene's dominant motion patterns by applying a peculiar bottom-up region-based segmentation algorithm to the direction model's blocks. Figure 5 shows the output of our algorithm on a  direction model with
direction model with  . We can see that neighbor blocks that have similar orientations appear in the same motion pattern. We can also note that traditional clustering algorithms cannot be applied here because a block can be in different motion patterns (cluster) at the same time. This situation happens frequently in real life such as zebra crossing and shop entrances. In addition, since we are processing circular data, the formulas need to be adapted to deal with the equality between 0 and
. We can see that neighbor blocks that have similar orientations appear in the same motion pattern. We can also note that traditional clustering algorithms cannot be applied here because a block can be in different motion patterns (cluster) at the same time. This situation happens frequently in real life such as zebra crossing and shop entrances. In addition, since we are processing circular data, the formulas need to be adapted to deal with the equality between 0 and  .
.

Motion pattern detection from a 3 × 3 direction model.
We propose a motion patterns extraction algorithm that deals with circular data. Another peculiarity of our algorithm is that it allows a block to be in different motion patterns; more specifically, a block can be in maximum of  clusters. This is done by considering two neighboring blocks in the same cluster if they have at least two similar orientations. In other words, at least one of the
clusters. This is done by considering two neighboring blocks in the same cluster if they have at least two similar orientations. In other words, at least one of the  major orientations at the first block has to be similar to at least one of the
major orientations at the first block has to be similar to at least one of the  major orientations of the second block. This is achieved by storing for each block the corresponding cluster for each dominant orientation. We use a 3D matrix with dimensions
major orientations of the second block. This is achieved by storing for each block the corresponding cluster for each dominant orientation. We use a 3D matrix with dimensions  and each element of that matrix will be affected by a cluster "id".
and each element of that matrix will be affected by a cluster "id".
The full algorithm is provided for clarification in Algorithm 1 and works as follows: a direction model  that has
that has  mixtures of
mixtures of  von Mises distributions and as its input and outputs a set of clusters
von Mises distributions and as its input and outputs a set of clusters  . We simplify the notation by introducing a 3D matrix
. We simplify the notation by introducing a 3D matrix  with size
with size  containing only the mean orientations of the direction model. Thus, an element
containing only the mean orientations of the direction model. Thus, an element  contains the mean orientation of the
contains the mean orientation of the  th von Mises distribution of the direction model block at position
th von Mises distribution of the direction model block at position  . Next, the algorithm initializes a
. Next, the algorithm initializes a  3D matrix
3D matrix  used to store the different cluster "id"s associated to the blocks. The next step consists of affecting the blocks to the corresponding regions, which is an iterative procedure. The algorithm uses 1-block neighboring and uses the similarity test explained earlier. The similarity condition between two orientations is satisfied if their difference is less than a threshold
used to store the different cluster "id"s associated to the blocks. The next step consists of affecting the blocks to the corresponding regions, which is an iterative procedure. The algorithm uses 1-block neighboring and uses the similarity test explained earlier. The similarity condition between two orientations is satisfied if their difference is less than a threshold . Experiments have demonstrated that a value of
. Experiments have demonstrated that a value of  gives the best balance between the algorithm's efficiency and effectiveness.
gives the best balance between the algorithm's efficiency and effectiveness.
Algorithm 1: Motion pattern detection.
-
1:
input Direction model D that contains
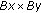 mixtures of
mixtures of  vM distributions
vM distributions -
2:
return Set of clusters
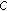
-
3:
Create a
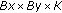 3D matrix
3D matrix  .
.  stores the cluster id of the corresponding
stores the cluster id of the correspondingelement
-
4:
Create a
 3D matrix
3D matrix  and initialize
and initialize 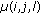 with the mean orientation of the
with the mean orientation of thel th vM distribution of the block at position
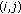
-
5:
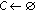
-
6:
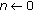
-
7:

-
8:
for
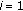 to
to 
-
9:
for
 to
to 
-
10:
for
 to
to 
-
11:
if

-
12:
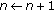
-
13:
create new cluster c
-
14:
put element
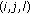 with orientation
with orientation 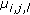 in
in  and update
and update 
-
15:
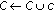
-
16:
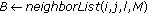
-
17:
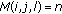
-
18:
for each
 in
in 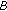
-
19:
if
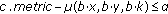
-
20:
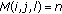
-
21:
put element
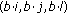 with orientation
with orientation 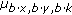 in
in  and update
and update 
-
22:

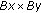 mixtures of
mixtures of  vM distributions
vM distributions
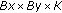 3D matrix
3D matrix  .
.  stores the cluster id of the corresponding
stores the cluster id of the corresponding 3D matrix
3D matrix  and initialize
and initialize 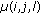 with the mean orientation of the
with the mean orientation of the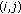

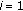 to
to 
 to
to 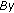
 to
to 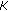

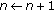
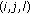 with orientation
with orientation 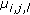 in
in  and update
and update 
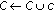
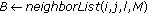
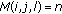
 in
in 
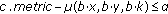
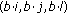 with orientation
with orientation 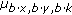 in
in  and update
and update 

5. Event Detection in Crowd Scenes
Our proposed method for event detection is based on the analysis of groups of people rather than individual persons. The targeted events occurring in groups of people are walking, running, splitting, merging, local dispersion, and evacuation.
The proposed algorithm is composed of several steps (Figure 6): it starts by building direction and magnitude models. After that, the block clustering step groups together neighboring blocks that have a similar orientation and magnitude. These groups are tracked over the next frames. Finally, the events are detected by using information from group tracking, the magnitude model, and the direction model.

Algorithm steps.
5.1. Direction and Magnitude Model
In this application, we are interested in real-time detection and group-tracking. Thus, for each frame we build a direction model which is called an instantaneous direction model. The steps involved in the estimation of the direction model are explained in Section 3.
The magnitude model is built using an online mixture of one-dimensional Gaussian distributions over the mean motion magnitude of a frame, given by

where  ,
,  , and
, and  are, respectively, the weight, mean, and variance of the
are, respectively, the weight, mean, and variance of the  th Gaussian which are learned from short sequences of walking persons. Hence, this magnitude model learns the walking speed of the crowd.
th Gaussian which are learned from short sequences of walking persons. Hence, this magnitude model learns the walking speed of the crowd.
5.2. Block Clustering
In this step, we gather similar blocks to obtain block clusters. The idea is to represent a group of people moving in the same direction at the same speed by the same block cluster. By "similar", we mean same direction, same speed, and neighboring locations. Each block  is defined by its position
is defined by its position  , and orientation
, and orientation  (see Section 5.1).
(see Section 5.1).
The merging condition consists of a similarity measure  between two blocks
between two blocks  and
and  defined as
defined as

Considering theses definitions, two neighboring blocks  and
and  are in the same cluster if
are in the same cluster if

where  is a predefined threshold. In our implementation, we choose
is a predefined threshold. In our implementation, we choose  empirically. Figure 7 shows a sample output of the process.
empirically. Figure 7 shows a sample output of the process.

Group clustering on a frame. Motion detectionEstimated direction modelDetected groups
The mean orientation  of the cluster
of the cluster  is given by the following formula [40]:
is given by the following formula [40]:

where  is the indicator function.
is the indicator function.
The centroid  of the group
of the group  is defined by
is defined by

and we obtain  by analogy.
by analogy.
5.3. Group Tracking
When the groups have been built, they are tracked in the next frames. The tracking is done by matching the centroids of the groups in a frame  with the centroids of the frame
with the centroids of the frame  . Each frame
. Each frame  is defined by its groups
is defined by its groups  where
where  is the number of groups detected in frame
is the number of groups detected in frame  . Each group
. Each group  is described by its centroid
is described by its centroid  and mean orientation
and mean orientation  . The group
. The group  that matches the group
that matches the group  must have the closest centroid to
must have the closest centroid to  and has to be in a minimal area around it. In other words, it has to satisfy these two conditions:
and has to be in a minimal area around it. In other words, it has to satisfy these two conditions:

where  is the minimal distance between two centroids (we choose
is the minimal distance between two centroids (we choose  ). If there is no matching (meaning no group
). If there is no matching (meaning no group  meeting these two conditions), then group
meeting these two conditions), then group  disappears and is no longer tracked in the next frames.
disappears and is no longer tracked in the next frames.
5.4. Event Recognition
The targeted events are classified into three categories.
-
(i)
Motion speed-related events: they can be detected by exploiting the motion velocity of the optical flow vectors across frames (e.g., running and walking events).
-
(ii)
Crowd convergence events: they occur when 2 or more groups of people get near to each other and merge into a single group (e.g., crowd merging event).
-
(iii)
Crowd divergence events: they occur when the persons move in opposite directions (e.g., local dispersion, splitting, and evacuation events).
The events from the first category are detected by fitting each frame's mean optical flow magnitude against a model of the scene's motion magnitude. The events from the second and third categories are detected by analyzing crowd's orientation, distance, and position. If two groups of people go to the same area, it is called "convergence". However, if they take different directions, it is called "divergence". In the following, we will give a more detailed explanation of the adopted approaches.
5.4.1. Running and Walking Events
As described earlier, the main idea is to fit the mean motion velocity between two consecutive frames against the magnitude model of the scene. It gives a probability for running  , walking
, walking  , and stopping
, and stopping  events. As motion flows are processed in this paper,
events. As motion flows are processed in this paper,  and
and  .
.
Since a person has more chances of staying in his current state rather than moving suddenly to the other state (e.g., a walking person increases his/her speed gradually until he/she starts running), then the final running or walking probability is a weighted sum of the current and previous probabilities. The result is compared against a threshold to infer a walking or a running event. Formally, a frame  with mean motion magnitude
with mean motion magnitude  contains a walking (resp., running) event if
contains a walking (resp., running) event if

where  (resp.,
(resp.,  ) is the walking (resp., running) threshold.
) is the walking (resp., running) threshold.  is the number of previous frames to consider. Each previous state has a weight
is the number of previous frames to consider. Each previous state has a weight  (in our implementation, we choose
(in our implementation, we choose  ,
,  , and
, and  ).
).  is the probability of observing
is the probability of observing  . It is obtained by fitting
. It is obtained by fitting  against the magnitude model (see Section 5.1) using formula (5). This probability is thresholded to detect a walking (resp., running) event. We choose a threshold of 0.05 for the walking event, and 0.95 for the running event, since there is 95% probability for a value to be comprised between
against the magnitude model (see Section 5.1) using formula (5). This probability is thresholded to detect a walking (resp., running) event. We choose a threshold of 0.05 for the walking event, and 0.95 for the running event, since there is 95% probability for a value to be comprised between  and
and  where
where  and
and  are, respectively, the mean and the standard deviation of the Gaussian distribution.
are, respectively, the mean and the standard deviation of the Gaussian distribution.
5.4.2. Crowd Convergence and Divergence Events
Convergence and divergence events are first detected by computing the circular variance  of the groups of each frame
of the groups of each frame  given the following equation [40]:
given the following equation [40]:

where  is the mean angle of the clusters in frame
is the mean angle of the clusters in frame  defined by
defined by

 is a value between 0 and 1 inclusive. If the angles are identical,
is a value between 0 and 1 inclusive. If the angles are identical,  will be equal to 0. A set of perfectly opposing angles will give a value of 1. If the circular variance exceeds a threshold
will be equal to 0. A set of perfectly opposing angles will give a value of 1. If the circular variance exceeds a threshold (we choose
(we choose  in our implementation), we can infer the realization of convergence and/or divergence events. We examine the position and direction of each group in relation with the other groups in order to decide which event happened. If two groups are oriented towards the same direction and are close to each other, then it is a convergence (Figure 8). However, if they are going in opposite directions and are close to each other, then it is a divergence.
in our implementation), we can infer the realization of convergence and/or divergence events. We examine the position and direction of each group in relation with the other groups in order to decide which event happened. If two groups are oriented towards the same direction and are close to each other, then it is a convergence (Figure 8). However, if they are going in opposite directions and are close to each other, then it is a divergence.

Merging groups.
More formally, let  be a vector representing a group
be a vector representing a group  at frame
at frame  .
.  is characterized by an origin
is characterized by an origin  which is the centroid of the group
which is the centroid of the group  , an orientation
, an orientation  , and a destination
, and a destination  whose coordinates
whose coordinates  ,
,  are defined as
are defined as

Two groups are converging (or merging) if the two following conditions are satisfied:

where  is the Euclidean distance between points
is the Euclidean distance between points  and
and  , and
, and  represents the minimal distance required between two groups' centroids (we took
represents the minimal distance required between two groups' centroids (we took  in our experiments). Figure 8 shows a representation of two groups participating in a merging event.
in our experiments). Figure 8 shows a representation of two groups participating in a merging event.
Similarly, two groups are diverging if the following conditions are satisfied:

However, in this situation, we distinguish three cases.
-
(1)
The groups do not stay separated for a long time and have a very short motion period; so they are still forming a group. This corresponds to the local dispersion event.
-
(2)
The groups stay separated for a long time and their distance grows over the frames. This corresponds to the crowd splitting event.
-
(3)
If the first situation occurs while the crowd is running, this corresponds to an evacuation event.
To detect the events described above, we add another feature to each group  which corresponds to its "age", represented by the first frame where the group appeared, noted by
which corresponds to its "age", represented by the first frame where the group appeared, noted by  . There is a local dispersion at frame
. There is a local dispersion at frame  between two groups
between two groups  and
and  if the conditions in (16) are satisfied. Besides, their motion has to be recent:
if the conditions in (16) are satisfied. Besides, their motion has to be recent:

where  is a threshold representing the number of frames since the groups have started moving (because group clustering relies on motion). In our implementation, it is equal to 28, which corresponds to 4 seconds in a 7 fps video stream.
is a threshold representing the number of frames since the groups have started moving (because group clustering relies on motion). In our implementation, it is equal to 28, which corresponds to 4 seconds in a 7 fps video stream.
Two groups  and
and  are splitting at frame
are splitting at frame  , if they satisfy the conditions (16). Moreover, at least one of them has a less recent motion:
, if they satisfy the conditions (16). Moreover, at least one of them has a less recent motion:

The evolution of the group separation over time from the local dispersion to the splitting event is illustrated in Figure 9.

Representation of local dispersion and splitting events.
There is an evacuation event between two groups  and
and  at frame
at frame  if they satisfy the local dispersion conditions (16) and (17) as well as the running conditions (11). Figure 10 shows a representation of two groups participating in an evacuation event.
if they satisfy the local dispersion conditions (16) and (17) as well as the running conditions (11). Figure 10 shows a representation of two groups participating in an evacuation event.

Representation of an evacuation event.
The probabilities of merging, splitting, local dispersion, and evacuating events noted, respectively, by  ,
,  ,
,  , and
, and  are null if the circular variance is less than the threshold, since the events are triggered only if the circular variance is greater than the threshold. In that case, merging, splitting, and dispersion probabilities are calculated by dividing the number of times the event occurred in a frame by the total number of times those three events occurred in the same frame. Let
are null if the circular variance is less than the threshold, since the events are triggered only if the circular variance is greater than the threshold. In that case, merging, splitting, and dispersion probabilities are calculated by dividing the number of times the event occurred in a frame by the total number of times those three events occurred in the same frame. Let  ,
,  , and
, and  be the number of times that merging, splitting, and local dispersion, respectively, occurred between the segments in frame
be the number of times that merging, splitting, and local dispersion, respectively, occurred between the segments in frame  . Then the merging probability for frame
. Then the merging probability for frame  is given by
is given by

We obtain  and
and  by analogy; for example,
by analogy; for example,  is defined by this formula:
is defined by this formula:

Since an event is what catches a user's attention, we consider that the most frequent events in a frame are the ones that characterize it. Thus, we considered a threshold of  for each event. This approach enables multiple events to occur for each frame but only keeps the most noticeable ones.
for each event. This approach enables multiple events to occur for each frame but only keeps the most noticeable ones.
Finally, the evacuation event probability at frame  , noted by
, noted by  , is a particular case because it is conditioned by the running event in addition to the local dispersion event. Therefore, if there is a running event in frame
, is a particular case because it is conditioned by the running event in addition to the local dispersion event. Therefore, if there is a running event in frame  (see Section 5.4.1), then
(see Section 5.4.1), then  is replaced by
is replaced by  in formula (20), and
in formula (20), and  is replaced by
is replaced by  .
.  and
and  are then equal to zero. If there is no running event in frame
are then equal to zero. If there is no running event in frame  ,
,  is null. The evacuation event threshold for each frame is also
is null. The evacuation event threshold for each frame is also  .
.
5.5. Event Detection Using a Classifier
We propose a methodology to detect the described events using a classifier. This is performed by using two classifiers, a first one for detecting motion-speed-related events and a second one for detecting crowd convergence and divergence events. Although this double labeling has the drawback of double processing, this is a more natural representation since we permit overlapping between events of different categories. For example, running and merging events can occur at the same frame. Another solution is to use a different classifier for each event. However, this solution is time-consuming and further processing needs to be performed in the case of an overlapping event between the merging and splitting events, for example.
Each classifier is trained by a set of features vectors where each one is estimated at each frame. Thus a classifier can classify an event for a frame given its feature vector. We use the running probability defined in Section 5.4.1 as a feature for the motion speed-related events classifier. The crowd convergence and divergence events classifier uses more features which are the running probability, the number of groups, their mean distance, their mean direction, and their circular variance.
6. Experiments
We show the experiments and the results of our approach in this section. We first focus on the motion pattern extraction experiments using videos from well-known datasets. After that, we experiment the crowd event detection approach using the PETS dataset.
6.1. Motion Pattern Extraction Results
The approach was experimented in various videos retrieved from different fields. The sequences have different complexities. They range from the simple case of structured crowd scenes where the objects behave in the same manner to the complex case of unstructured crowd scenes where different motion patterns can occur at the same location on the image plane. To process a video sequence, we estimate its optical flow vectors in order to build a direction model. The motion pattern extraction is then run on that direction model.
Our approach was first experimented in an urban environment where vehicles and pedestrians use the same road (Figure 11). The sequence was retrieved from the AVSS 2007 dataset (http://www.elec.qmul.ac.uk/staffinfo/andrea/avss2007_d.); it has a resolution of  pixels with a sampling rate of 25 Hz. It consists of a two-way road, the traffic flow being on the left side of the road. Vehicles operate on the road and some pedestrians cross it. The proposed approach retrieved the car patterns successfully by retrieving two classes for the traffic flow and a third direction for cars turning left. In addition, it also retrieved the pedestrians' patterns at the bottom of the scene. The advantage of affecting multiple clusters to a single block can be noted in comparison with other approaches where a unique orientation is assumed for each location in the scene.
pixels with a sampling rate of 25 Hz. It consists of a two-way road, the traffic flow being on the left side of the road. Vehicles operate on the road and some pedestrians cross it. The proposed approach retrieved the car patterns successfully by retrieving two classes for the traffic flow and a third direction for cars turning left. In addition, it also retrieved the pedestrians' patterns at the bottom of the scene. The advantage of affecting multiple clusters to a single block can be noted in comparison with other approaches where a unique orientation is assumed for each location in the scene.

Major motion patterns in an urban scene.
Figure 12 shows a crowd performing a pilgrimage. In this video, a huge amount of people browse the area in different directions. However, our algorithm detects two major motion patterns despite the complexity of the sequence. This is explained by research in collective intelligence which states that moving organisms generate patterns over time and a certain order is generated instead of chaos.

Detected motion patterns in a pilgrimage sequence. Original frameDetected motion patterns
We compare our approach to [18] which proposed a motion pattern extraction method by clustering the motion field. We show its results to the "Motion Field approach" using the Hadjee sequence in Figure 13, where we see that our approach has better results. In fact, our methodology supports the overlapping of motion patterns as opposed to [18] where the brown and orange patterns did not overlap. We also remark that the "Motion Field approach" detects less motion at the top of the frame because it uses a preprocessing step which may eliminate useful motion information.

Detected motion patterns in a pilgrimage sequence using the Motion Flow Field [ 18 ].
Next, we show the results of our approach using a complex scene with both cars and people moving as illustrated in Figure 14. These sequences are retrieved from the Getty-images (http://www.gettyimages.com/) website. It contains three two-way roads on the left, middle, and right parts of the sequence, respectively. In addition, there are two long zebras that cross the roads. We detected most of the motion patterns which are illustrated in Figure 14(b). However, in the areas where the optical flow vectors are not precisely estimated, we could not detect the motion patterns such as the zebra crossing at the back of the scene.

Detected motion patterns in complex sequence with moving cars and people. Original frameMotion patterns
We show more results of our approach using various video sequences in Figures 15 and 16. They are retrieved from video search engines, CAVIAR dataset, and Getty-images website. The sequences are characterized by a high density of moving objects.

Detected motion patterns in another pilgrimage sequence. Original frameMotion patterns

Detected motion patterns at the bottom of an escalator. Original frameMotion patterns
Finally, we synthesize the results of our experiments in Table 1 which compares the number of detected motion patterns with the ground truth. We provide the original file names of the sequences. Note that providing only the number of motion patterns is insufficient, and we must also provide an illustration of the detected motion patterns for each sequence. Nevertheless, the evaluation of a motion pattern extraction approach remains subjective and different appreciations may be made for the same video. However, we believe that our approach provides satisfying results given the complexity of the sequences.
6.2. Event Detection
The approach described in the previous sections has been evaluated in the PETS'2009 datasets. This dataset includes multisensor sequences containing different crowd activities. Several scenarios involving crowd density estimation, crowd counting, single person tracking, flow analysis, and high-level event detection are proposed. Also, a set of training data is available.
For this paper, we processed the event recognition sequences which are organized in the S3 dataset. The algorithm processed five  video streams at a speed of 4 frames/second on an Intel Celeron 1.8 GHZ. We used a block size of 15 pixels which is the best balance between efficiency and effectiveness.
video streams at a speed of 4 frames/second on an Intel Celeron 1.8 GHZ. We used a block size of 15 pixels which is the best balance between efficiency and effectiveness.
In our experiments, we collected the 1000 frames of the dataset and we annotated them with two labels. The first one is either running or walking. The second one is split, local dispersion, merge, evacuation, or regular. Figure 18 illustrates each event in a separate image. The local dispersion event is represented in Figure 18(e) by a pink line that links the corresponding groups, merging is represented in Figure 18(c) by a yellow line, and splitting is represented in Figure 18(d) by a white line.
Since each frame has two labels, two classifiers are necessary. This has the drawback of increasing the computation costs. However, we are able to detect two categories of events such as the frames where the running and merging events occur. The dataset was split into a training set (75%) and a testing set (25%). For both categories of events, the random forest classifier performed best. We show the confusion matrices in Figure 17.

Confusion matrices obtained using random forest classifier: (a) running and walking events, and (b) splitting, merging, evacuation, and local dispersion events.

Event detection samples. The numbers represent the probabilities of the events. Detected events are colored in blue.Walking eventRunning eventMerging eventSplitting eventLocal dispersion eventEvacuation event
We assemble the results obtained using manual parameters and classifiers as well as the results of other approaches in Table 2. It shows the precision and the recall, if available, for each event. We note that our approach (manual parameters or classifiers) is the only one which is able to detect all of the events. The approach using Statistical filters detects only 3 events and the Holistic Properties approach which does not consider the regular event (which is confused with walking).
The statistical filters approach was designed to detect "abnormal behavior" by using the unusual flow and unusual magnitude features. These features can only detect three categories of events (regular, split, and running). However, the authors claim that their approach is able to detect other events by plugging other features. Unfortunately, no more details are provided on how to plug other features. In addition, we believe that the features modelling all types of behaviors are better than features modelling only abnormal behaviors. Table 2 shows that our approach has the same results as the approach using statistical filters and has also the advantage of detecting more events "out of the box".
The results of our approach are very close to the Holistic properties approach [42]. However, this approach is slower than ours and does not permit the overlapping of events, which means that we cannot have walking and merging events at the same instant.
7. Conclusion
We have presented an automatic visual surveillance system able to detect major motion patterns and events in crowd scenes. It bypasses time-consuming methods such as background subtraction and person detection and rather resorts to global motion information obtained from optical flow vectors to model the motion magnitude and velocity at each spatial location of the scene. These models use mixture distributions estimated via online algorithms in order to capture multimodal crowd motion over time. Motion patterns are then detected by applying a region-based segmentation algorithm to the direction model of a video stream. Crowd events are detected by analyzing the behavior of the groups in terms of motion direction and velocity.
We demonstrate the performance of our approach using multiple datasets. These experiments show that our approach is applicable to a wide range of scenes which consist of low and high crowd density scenes as well as structured and unstructured (i.e., the motion of crowd at any location is multimodal) scenes. In addition, the system detects groups of people even in the presence of occlusions, which then facilitates the detection of group-related events such as merging or splitting.
In the future, we plan to address some specific problems in order to improve the results like, for instance, performing a finer analysis of the notion of block, adjusting the size of the blocks to the spatiotemporal motion features, or adopting a multiscale approach. Besides, we plan to extend the research domains of our system. More precisely, we will use detected motion patterns as a prerequisite for tracking single persons and detecting abnormal behaviors. Furthermore, we will label the video streams using semantic information retrieved from the event detection module in order to add indexing/retrieval capabilities to our system.
References
Shyu ML, Xie Z, Chen M: Video semantic event/concept detection using a subspace-based multimedia datamining framework. IEEE Transactions on Multimedia 2008, 10: 252-259.
Sternberg R: Cognitive Psychology. 3rd edition. Thomson Wadsworth; 2003.
Bahlmann C: Directional features in online handwriting recognition. Pattern Recognition 2006, 39(1):115-125. 10.1016/j.patcog.2005.05.012
Robert TC, Lipton AJ, Kanade T: Introduction to the special section on video surveillance. IEEE Transactions on Pattern Analysis and Machine Intelligence 2000, 22(8):745-746. 10.1109/TPAMI.2000.868676
Zhan B, Monekosso DN, Remagnino P, Velastin SA, Xu LIQ: Crowd analysis: A survey. Machine Vision and Applications 2008, 19(5-6):345-357. 10.1007/s00138-008-0132-4
Baumann A, Boltz M, Ebling J, Koenig M, Loos HS, Merkel M, Niem W, Warzelhan JK, Yu J: A review and comparison of measures for automatic video surveillance systems. Eurasip Journal on Image and Video Processing 2008, 2008:-30.
Hu W, Tan T, Wang L, Maybank S: A survey on visual surveillance of object motion and behaviors. IEEE Transactions on Systems, Man and Cybernetics C 2004, 34(3):334-352. 10.1109/TSMCC.2004.829274
Morris BT, Trivedi MM: A survey of vision-based trajectory learning and analysis for surveillance. IEEE Transactions on Circuits and Systems for Video Technology 2008, 18(8):1114-1127.
Li L, Huang W, Gu IYH, Tian Q: Foreground object detection from videos containing complex background. In Proceedings of the eleventh ACM international conference on Multimedia (MULTIMEDIA '03), 2003, New York, NY, USA. ACM; 2-10.
Stauffer C, Grimson WEL: Adaptive background mixture models for real-time tracking. Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR '99), June 1999 2: 246-252.
Kaewtrakulpong P, Bowden R: An improved adaptive background mixture model for realtime tracking with shadow detection. Proceedings of the 2nd European Workshop on Advanced Video Based Surveillance Systems, 2001
Birchfield S: Klt: an implementation of the kanade-lucas-tomasi feature tracker. 2006
Bouguet J-Y: Pyramidal implementation of the lucas kanade feature tracker description of the algorithm. 2000
Shi J, Tomasi C: Good features to track. Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR '94), June 1994 593-600.
Hu W, Xiao X, Fu Z, Xie D, Tan T, Maybank S: A system for learning statistical motion patterns. IEEE Transactions on Pattern Analysis and Machine Intelligence 2006, 28(9):1450-1464.
Wang X, Tieu K, Grimson E: Learning semantic scene models by trajectory analysis. Proceedings of the 9th European Conference on Computer Vision (ECCV '06), 2006, Lecture Notes in Computer Science 3953:
Basharat A, Gritai A, Shah M: Learning object motion patterns for anomaly detection and improved object detection. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR '08), June 2008 1-8.
Hu M, Ali S, Shah M: Learning motion patterns in crowded scenes using motion flow field. Proceedings of the 19th International Conference on Pattern Recognition (ICPR '08), December 2008
Zhang T, Lu H, Li SZ: Learning semantic scene models by object classification and trajectory clustering. Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition Workshops (CVPR '09), June 2009 1940-1947.
Yu Q, Medioni G: Motion pattern interpretation and detection for tracking moving vehicles in airborne video. Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition Workshops (CVPR '09 ), June 2009 2671-2678.
Lin D, Grimson E, Fisher J: Learning visual flows: a lie algebraic approach. Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition Workshops (CVPR '09), June 2009 747-754.
Gryn JM, Wildes RP, Tsotsos JK: Detecting motion patterns via direction maps with application to surveillance. Computer Vision and Image Understanding 2009, 113(2):291-307. 10.1016/j.cviu.2008.10.006
Rodriguez M, Ali S, Kanade T: Tracking in unstructured crowded scenes. Proceedings of the 12th International Conference on Computer Vision (ICCV '09), October 2009, Kyoto, Japan 1389-1396.
Stauffer C, Grimson WEL: Learning patterns of activity using real-time tracking. IEEE Transactions on Pattern Analysis and Machine Intelligence 2000, 22(8):747-757. 10.1109/34.868677
Morris B, Trivedi M: Learning trajectory patterns by clustering: experimental studies and comparative evaluation. Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition Workshops (CVPR '09), June 2009 312-319.
Eibl G, Brändle N: Evaluation of clustering methods for finding dominant optical flow fields in crowded scenes. Proceedings of the 19th International Conference on Pattern Recognition (ICPR '08), December 2008
Ma Y, Cisar P, Kembhavi A: Motion segmentation and activity representation in crowds. International Journal of Imaging Systems and Technology 2009, 19(2):80-90. 10.1002/ima.20184
Kratz L, Nishino KO: Anomaly detection in extremely crowded scenes using spatio-temporal motion pattern models. Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition Workshops (CVPR '09), June 2009 1446-1453.
Andrade EL, Blunsden S, Fisher RB: Hidden Markov Models for optical flow analysis in crowds. Proceedings of the 18th International Conference on Pattern Recognition (ICPR '06), August 2006 1: 460-463.
Andrade EL, Blunsden S, Fisher RB: Modelling crowd scenes for event detection. Proceedings of the 18th International Conference on Pattern Recognition (ICPR '06), August 2006, Washington, DC, USA 175-178.
Ali S, Shah M: A Lagrangian particle dynamics approach for crowd flow segmentation and stability analysis. Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR '07), June 2007 1-6.
Li J, Gong S, Xiang T: Scene segmentation for behaviour correlation. Proceedings of the European Conference on Computer Vision (ECCV '08), 2008
Wang X, Ma X, Grimson WE: Unsupervised activity perception in crowded and complicated scenes using hierarchical bayesian models. IEEE Transactions on Pattern Analysis and Machine Intelligence 2009, 31(3):539-555.
Ihaddadene N, Djeraba C: Real-time crowd motion analysis. Proceedings of the 19th International Conference on Pattern Recognition (ICPR '08), December 2008
Mehran R, Oyama A, Shah M: Abnormal crowd behavior detection using social force model. Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition Workshops (CVPR '09), June 2009 935-942.
Adam A, Rivlin E, Shimshoni I, Reinitz D: Robust real-time unusual event detection using multiple fixed-location monitors. IEEE Transactions on Pattern Analysis and Machine Intelligence 2008, 30(3):555-560.
Wright J, Pless R: Analysis of persistent motion patterns using the 3D structure tensor. Proceedings of the IEEE Workshop on Motion and Video Computing (WMVC '05), January 2005, Washington, DC, USA 2: 14-19.
Harris C, Stephens MJ: A combined corner and edge detector. Proceedings of the Alvey Vision Conference, 1988, Washington, DC, USA 147-152.
Lucas B, Kanade T: An iterative image registration technique with an application to stereo vision. Proceedings of the International Joint Conference on Artificial Intelligence, 1981, Washington, DC, USA 674-679.
Gary L, Gaile L, James EB: Directional Statistics, Concepts and Techniques in Modern Geography. Geo Abstracts, Norwich, UK; 1980.
Kiss A, Utasi A, Sziranyi T: Statistical filters for crowd image analysis. Proceedings of the 11th IEEE International Workshop on Performance Evaluation of Tracking and Surveillance (PETS '09), February 2009
Chan AB, Morrow M, Vasconcelos N: Analysis of crowded scenes using holistic properties. Proceedings of the 11th IEEE International Workshop on Performance Evaluation of Tracking and Surveillance (PETS '09), 2009
Acknowledgment
This work has been supported by the European Commission within the Information Society Technologies program (FP6-IST-5-0033715), through the project MIAUCE (http://www.miauce.org/) and the French ANR project CAnADA.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
Open Access This article is distributed under the terms of the Creative Commons Attribution 2.0 International License (https://creativecommons.org/licenses/by/2.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
About this article
Cite this article
Benabbas, Y., Ihaddadene, N. & Djeraba, C. Motion Pattern Extraction and Event Detection for Automatic Visual Surveillance. J Image Video Proc. 2011, 163682 (2011). https://doi.org/10.1155/2011/163682
Received:
Revised:
Accepted:
Published:
DOI: https://doi.org/10.1155/2011/163682